


الگوریتم هوشمند پیشبینی کننده اوضاع جوی دیپمایند
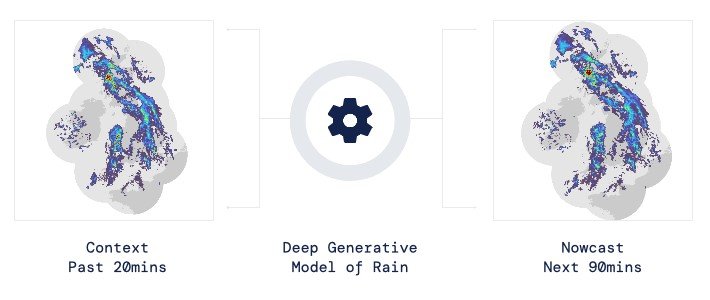
شرکت دیپمایند موفق به ساخت الگوریتم هوشمندی شده که nowcasting نام دارد. الگوریتمی که میتواند وضعیت آب و هوا را با سطح جدیدی از دقت پیشبینی کند. عملکرد الگوریتم فوق به گونهای است که از فناوری راداری و با وضوح ۱ کیلومتر هر پنج دقیقه یک بار وضعیت بارندگی را دنبال میکنند. دیپمایند این کار را با استفاده از رویکرد مدلسازی زایا انجام داده است. در این روش وضعیت رادار در ۲۰ دقیقه گذشته مورد تحلیل قرار میگیرد و ۹۰ دقیقه آینده را پیشبینی میکند. این ابزار بر بارشهای ملایم تا سنگین تمرکز میکند که بیشترین اثر بر شهرها و اقتصاد را دارند. تیم محققان دیپمایند میگویند روش جدید آنها برتری قابل توجهی نسبت به مدلهای فعلی دارد. شکل 1عملکرد این سامانه را نشان میدهد. در این پروژه تحقیقاتی بیش از ۵۰ کارشناس هواشناسی از سرویس ملی هواشناسی بریتانیا به همراه برجستهترین محققان این شرکت حضور داشتهاند. ابزار مدل زایای عمیق بارانی در ۸۹ درصد مواقع نسبت به سایر روشهای پیشبینی آب و هوا بهتر عمل میکند (شکل 2).
شکل 1

شکل 2
اکنون دیپمایند در نظر دارد با بهبود دقت پیشبینیهای بلندمدت و بارندگیهای شدید سیستم خود را ارتقا داده و نتایج بهتری کسب کند. این شرکت معتقد است با استفاده از تحلیلهای آماری، اقتصادی و شناختی میتواند راهکار جدیدی برای پیشبینی وضعیت آب و هوا از روی رادارها ارایه کند. دیپمایند قصد دارد در آینده به توسعه روشهایی برای ارزیابی توانایی سیستمها و به کارگیری آنها در محیطهای واقعی بپردازد. برنامهریزی و مدیریت در بیشتر سیستمهای آبی و بهطور کلی مصرف منابع آب به شکل سالم و مداوم برای مدیریت مخازن، مهار سیلابها و تامین آب موردنیاز کشاورزان، واحدهای صنعتی و خانگی اجتنابناپذیر و نیازمند پیشبینی بارندگی در فواصل زمانی مشخص است. بارش پدیدهای است که تابع عوامل مختلفی است که پیشبینی این عوامل به روشهای معمول آماری سخت و غیر دقیق است. بر همین اساس سازمانهای مسئول در این زمینه از هوش مصنوعی و با استخراج دادههای ایستگاههای مختلف سعی میکنند مدلی برای پیشبینی بارندگی در فصول مختلف سال به دست آورند. مزیت بزرگ الگوریتمهای هوشمند نسبت به توابع پیچیده ریاضی در دسترس بودن دادهها است. به بیان دقیقتر، کافی است مدل را به گونهای آموزش دهید که توانایی درک دادهها را داشته باشد. در ادامه الگوریتم قادر خواهد بود پیشبینی دقیقی در این زمینه ارایه کند.
یکی از مفاهیم مهم در این زمینه هیدرولوژی (Hydrology) به معنای آبشناسی است که از دو واژه Hydro به معنی آب و Logos به معنی شناسایی تشکیل شده و به معنای علم آب است. یعنی علمی که در مورد پیدایش، خصوصیات و نحوه توزیع آب در طبیعت بحث میکند. هیدرولوژیستها (آبشناسان) سالیان متمادی است که سعی در درک و پیشبینی دقیق فرایندهای جوی برای تامین آب و کنترل سیلابها و موارد این چنینی دارند، به دلیل اینکه پیشبینی در مدیریت منابع آب اهمیت زیادی دارد.
شبیهسازی و پیشبینی در گامهای زمانی روزانه برای پارامترهای هیدرولوژیکی به خصوص جریان آب روزانه (streamflow) و سطح آب با مرتبه دقت بالا در مقیاس حوضچه، نقش کلیدی در روند مدیریت سیستمهای منابع آب دارد. مدلهای قابل اطمینان و پیشبینیها میتواند به عنوان یک راهحل توسط نهادها و سازمانهایی مثل وزارت نیرو در تخصیص منابع آبی در میان گروههایی از جامعه مثل کشاورزان، واحدهای صنعتی و خانگی مورد استفاده قرار گیرد. استخراج ویژگیهای حوضچه از جنبههای مهم در هر فرایند پیشبینی و مدلسازی هیدرولوژیکی است. عملکرد روشهای مدلسازی و طرحریزی برای ایستگاه هیدرومتری با توجه به منطقه آب و هوایی حوضه آبریز و ویژگیهای حوضه متفاوت است. هیدرولوژیستها سالها است در تلاش هستند هستند تا درک و پیشبینی دقیقی از فرایندهای جوی برای تامین آب و کنترل سیلاب و موارد این چنینی بهدست آورند و همانگونه که مشاهده کردیم، شرکتهای بزرگی مثل دیپمایند به دنبال به بهترین روشها هستند. جالب آنکه دیپمایند در انگلستان است و به لحاظ طبیعی این کشور نیازی به پیشبینی و کنترل منابع آبی ندارند، اما همانگونه که اشاره شد، بحران آب کاملا جدی است و همه کشورها به دنبال ذخیرهسازی این منبع استراتژیک هستند.
متاسفانه روشهایی که برای مدلسازی جریان آب در مناطق پر آب طراحی شده و استفاده میشوند در کشورهای واقع در نواحی خشک عملکرد چندان مطلوبی ندارد، زیرا کمبود آب در کشورهای خشک به دلیل ماهیت متناوب الگوهای جوی تقریبا یکسان است. خصوصیات آب و هوایی بر عملکرد روشهای مختلف پیشبینی در حوزههای مختلف تاثیرگذار هستند و به همین دلیل است که امکان ارایه یک الگوی واحد برای همه کشورها وجود ندارد. درک الگوی آبوهوایی و پویایی سفرههای آب زیرزمینی عوامل مهمی هستند که الگوریتمهای هوشمند میتوانند با تحلیل آنها اطلاعات جامعی در اختیار متخصصان قرار دهند. شبیهسازی این مکانیسمها و روابط میتواند با مدلهای فیزیکی، مفهومی یا دادهها اجرا شود. علاوه بر این برای ساخت یک مدل دقیق به مجموعهای گسترده از دادهها نیاز است که دستیابی به آنها دشوار است، زیرا بهطور طبیعی برای دسترسی به این مجموعه دادهها به مجوزهای دولتی نیاز است. بهطور کلی، مدلهای فیزیکی و مفهومی برای اجرا با سختیهای زیادی روبرو هستند و برای آنکه نتایج دقیقی ارایه کنند به حجم گستردهای از اطلاعات نیاز دارند. از طرفی بیشتر فرایندهای هیدرولویکی غیر خطی و مبتنی بر تابع قوانین فرایندهای تصادفی هستند. هیدرولوژیستها مدلهایی که امروزه در هیدرولوژی استفاده میشوند را به سه گروه مدلهای ریاضی-فیزیکی، مدلهای ژئومورفولوژیکی و مدلهای تجربی تقسیم کرده است.
گروه اول، مدلهایی مبتنی بر ویژگیهای فیزیکی سیستم هستند و در قالب معادلات دیفرانسیل بیان میشوند. گروه دوم مبتنی بر ویژگیهای ژئومورفولوژیکی هستند و سیستم هیدرولوژیکی موردنظر را شرح میدهند. این نوع مدلها توانایی زیادی در شبیهسازی الگوی رفتاری حوزه آبریز و شبکههای آبیاری و زهکشی دارند. گروه سوم مدلهای تجربی هستند که بدون توجه به پارامترها سعی میکنند رابطه میان ورودی و خروجی را نشان دهند. این مدلها بهنام مدلهای واریانسی نیز معروف هستند. کارشناسان حوزه آبوهاویی در کشورهای مختلف از هوش مصنوعی و شبکههای عصبی که در گروه مدلهای تجربی قرار میگیرند و توانایی زیادی در مدلسازی پدیدهای غیر خطی دارند استفاده میکنند. بهطوری که اولین نمونه از این مدلها که سیستمی برای تخمین میزان بارندگی بود در سال 1992 توسط فرنچ و تیمی از پژوهشگران پدید آمد. نزدیک به دو سال بعد توما و ایگاتا از طریق بهکارگیری یک شبکه سه لایهای و دادههای ماهوارههای سنجش از راه دور، توانستند به پیشبینی بارش در برخی سواحل ژاپن بپردازند. این گروه از یک لایه پنهان، روند آموزش انفصالی و تکنیک انتشار سطحی سود بردند. کلید موفقیت این گروه استفاده از پارامترهای هواشناسی در تخمین بارش بود. این روند ادامه پیدا کرد تا در نهایت پژوهشگران از شبکههای MLP سرنام MultiLayer Perceptron و RBF سرنام Radial Basis Function برای پیشبینی و تاثیر تاخیر گامهای زمانی در میزان بارندگی استفاده کردند. بهطور کلی در فرایند مدلسازی، پژوهشگران از شبکههای MLP استفاده میکنند. شیوه کار به این صورت است که ابتدا فرایند نرمالسازی دادههای ورودی به شبکه آغاز میشود. در ادامه از توابع نرمالسازی رایج استفاده شده و تاثیر آنها در شبکه بررسی میشود. یکی از رایجترین نرمالسازیهای رابطه فرمول زیر است که میانگین دادهها را صفر و واریانس آنها را یک میکند.
البته رابطههای دیگری نیز وجود دارند که هر یک بر مبنای ساختار دادهای طراحی شده استفاده میشوند. برخی کارشناسان پیشنهاد میکنند به دلیل کوتاه بودن حافظه فعال بارندگی (شدت و کاهش بارشها) دادهها از طریق فرمول زیر به یک فضای لگاریتمی انتقال پیدا کند.
البته برای آنکه نتایج دقیقتری به دست آید لازم است بهترین تابع نرمالسازی استفاده شود تا بتواند دادهها را به فضای لگاریتمی و برد مشخص انتقال دهد. بهطور کلی هدف از بهکارگیری توابع لگاریتمی کاهش دامنه نوسان دادهها است. یک تابع نرمالساز دقیقتر در این زمینه میتواند مبتنی بر فرمول زیر باشد:
- پس از نرمالسازی دادهها، شبکهای برای صحتسنجی دادهها طراحی میشود و از طریق پارامترهای هر ماه میزان بارندگی همان ماه تخمین زده میشود. بهطور معمول در این شبکه، ضریب همبستگی r2 بهطور میانگین برابر با 98 درصد در نظر گرفته میشود که بیانگر خطای کم در داده است. در مرحله بعد شبکههایی با تعداد لایهها و سلولهای عصبی مختلف ایجاد میشود. برای مدلسازی، دادههای نرمال شده به سه گروه آموزشی، صحتسنجی و آزمون تقسیم میشوند و درصدهایی به آنها تخصیص داده میشود. برای اطمینان از کارکرد درست الگوریتم، از هر مدل نمونههای مختلفی ساخته شده و در نهایت بهترین گزینه انتخاب میشود. شبکههای مبتنی بر یک تا سه لایه پنهان و توابع انتقال سیگموئید و خطی تا 6 سلول عصبی در لایه پنهان با کمترین خطا نتایج را ارایه میکنند و پس از آن از ضریب دقت آنها کاسته میشود. در مدلهای مبتنی بر یک لایه پنهان که از توابع انتقال سیگموئید استفاده میکنند، روند کاهنده خطا تا 8 سلول عصبی در لایه پنهان وجود دارد و پس از آن روند افزایش خطا را شاهد هستیم. نکته مهمی که باید در مورد پیادهسازی شبکههای مبتنی بر لایه پنهان به آن دقت کنید، میزان خطای آنها است. در مدلهای مبتنی بر یک لایه پنهان که توابع انتقال آنها سیگموئید است، روند کاهنده خطا تا 8 سلول عصبی در لایه پنهان ادامه داشته و در ادامه روند افزایش خطا ایجاد میشود. همانگونه که مشاهده میکنید در زمان ساخت شبکههای عصبی بر مبنای لایه پنهان باید به آهنگ دقیق کاهنده یا افزاینده بودن میزان خطا دقت کنید. در غیر این صورت خروجی مدل قابل استناد نیست. بهطور مثال، در برخی پروژهها هرچه تعداد لایههای پنهان بیشتر باشد، شبکه با خطای بیشتری کار میکند و بنابراین در برخی مدلها نباید بیش از سه لایه پنهان را بهکار گرفت. دومین نکته مهمی که باید به آن دقت کنید توابع انتقال هستند که باید به دقت بررسی شوند. بهطور مثال، در پیشبینی بارشها تابع سیگموئید عملکرد بهتری نسبت به نمونههای مشابه دارد. پس از آنکه شبکه عصبی برای تخمین میزان بارش ماهانه مشخص شد، در ادامه باید از میان پارامترهای در دسترس، بهترین آنها را انتخاب کرد. از مهمترین پارامترها در این زمینه باید به افزایش درجه حرارت در آینده، متوسط دما، کمینه و بیشینه دما، میانگین فشار هوا، میانگین بخار آب، محاسبه تعداد روزهای بارش بر مبنای میانگینهای مختلف بارندگی، رطوبت نسبی، سرعت باد، جهت باد، سرعت باد و تعداد روزهای آفتابی اشاره کرد.
کلام آخر
پیشبینی نیازها و استفاده از آب باید قبل از تجزیه و تحلیل تغییرات درازمدت برای پارامترهای مرتبط با آن، برای بهبود روند توسعه سناریوهای جدید، برای منابع آب سطحی یا آبهای زیرزمینی انجام شود. مقیاس گسترده تجزیه و تحلیل شهری، دادههای تلفیقی و مرحله حدود علم تحلیل دادهها بهتر است از شبکههای عصبی پیچیده عمیق (DeepCNNs) استفاده کنند. بهطور معمول، پژوهشگران میتوانند از یک برنامه سه مرحلهای برای پیشبینی جریان آب و سطح آب استفاده کنند. مرحله اول تجزیه و تحلیل دادهها در سطح گستردهای در مقیاس شهری انجام میشود که خود از دو مرحله (الف و ب) تشکیل میشود. مرحله الف استفاده از مدل تعادل آب توزیع مکانی فضایی و یکپارچهسازی تغییرات آب و هوایی و کاربری زمین است. این مرحله از طیف گستردهای از پارامترهای ورودی و شبکهها از جمله متغیرهای فصلی محیطی و تغییرات آن، کاربری زمین و پارامترهای فصلی آن و تغییرات آینده، عمق فصلی آب زیرزمینی، ویژگیهای خاک، توپوگرافی و شیب استفاده میکند. خروجی این مرحله چند پارامتر شامل رواناب، تغذیه، رهگیری، تبخیر تعرق، تبخیر خاک و در تعادل آب را شامل میشود. پژوهشگران میتوانند از این مرحله به عنوان یک ویژگی استخراج شده برای ذخیرهسازی دادهها استفاده کنند. در مرحله ب، دادههای مربوطه به کمینه و بیشینه باید از ایستگاههای هواشناسی در یک بازه زمانی ده یا بیست ساله جمعآوری شوند. علاوه بر این دما نیز با استفاده از مدلهای مقیاس آماری پایین شبیهسازی شوند. در مرحله دوم، باید ویژگیهای استخراج شده از مرحله قبل با دو خروجی قابل مشاهده برای جریان آب و سطح آب در دو دهه قبل جمعآوری شود. علاوه بر این، باید دادهها نرمالسازی و مقیاسبندی شوند و آنها را ذخیرهسازی کنیم تا برای مرحله بعدی پردازش شود. در مرحله سوم تجزیه و تحلیل دادههای دانش دامنه قرار دارد که در آن ویژگیهای ذخیرهسازی شده استفاده میشوند و مدل پیشنهادی همراه با مدلهای پایه برای پیشبینی جریان آب و سطح آب در سراسر ایستگاههای آب استفاده میشوند
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.






















نظر شما چیست؟