


علم داده چیست؟
علم داده ترکیبی از آمار، ریاضیات، برنامههای تخصصی، هوش مصنوعی، یادگیری ماشین و غیره است. علم داده به استفاده از اصول خاص و تکنیکهای تحلیلی برای استخراج اطلاعات از دل دادههای خام با هدف استفاده از آنها در برنامهریزی استراتژیک، تصمیمگیری و غیره میپردازد. به بیان سادهتر، علم داده بهمعنی تجزیهوتحلیل دادهها با هدف دستیابی به بینشهای عملی است. با این مقدمه به سراغ پرطرفدارترین پرسشهای استخدامی دانشمند علم داده میرویم که انتظار میرود در جلسههای استخدامی با آنها روبهرو شوید. برای کمک به خوانندگان پاسخها نیز گردآوری شدهاند.
1. چه تفاوتی میان یادگیری تحت نظارت و بدون نظارت وجود دارد؟
یادگیری تحت نظارت از دادههای شناختهشده و برچسبگذاریشده بهعنوان ورودی استفاده میکند و مبتنی بر مکانیزم بازخوردی است. از الگوریتمهای رایج یادگیری تحت نظارت باید به درخت تصمیم، رگرسیون لجستیک و ماشین بردار پشتیبان اشاره کرد. در نقطه مقابل، یادگیری بدون نظارت از دادههای بدون برچسب بهعنوان ورودی استفاده میکند و فاقد مکانیزم بازخوردی است. از الگوریتمهای رایج یادگیری بدون نظارت، باید به خوشهبندی k-means، خوشهبندی سلسله مراتبی و الگوریتم اپریوری (Apriori Algorithm) اشاره کرد.
مطلب پیشنهادی
 آشنایی با رشته دادهمحور علم دادهها
آشنایی با رشته دادهمحور علم دادهها
مطلب پیشنهادی
2. رگرسیون لجستیک چگونه انجام میشود؟
رگرسیون لجستیک رابطه بین متغیر وابسته (برچسب آن چیزی که قصد پیشبینی آنرا داریم) و یک یا چند متغیر مستقل (ویژگیهای مدنظر ما) را با تخمین احتمال با استفاده از تابع لجستیک زیربنایی آن (سیگموئید) اندازهگیری میکند. شکل ۱، نحوه عملکرد رگرسیون لجستیک را نشان میدهد.
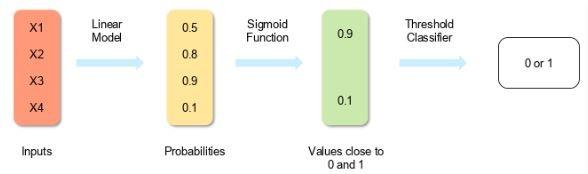
شکل 1
فرمول و نمودار تابع سیگموئید در شکل ۲ نشان داده شده است.
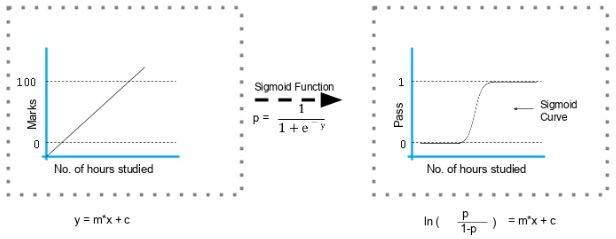
شکل 2
3. مراحل ساخت درخت تصمیم را توضیح دهید
- کل مجموعه داده را بهعنوان ورودی در نظر بگیرید.
- آنتروپی متغیر هدف و ویژگیهای پیشبینیکننده را محاسبه کنید.
- از تکنیک به دست آوردن اطلاعات (Information Gain) برای محاسبه همه ویژگیها استفاده کنید.
- ویژگیای را که بالاترین اطلاعات دارد، بهعنوان گره ریشه انتخاب کنید.
- همین رویه را در هر شاخه تکرار کنید تا زمانی که گره تصمیم هر شاخه نهایی شود.

بهعنوان مثال، فرض کنید میخواهید یک درخت تصمیم بسازید تا تصمیم بگیرید که آیا باید یک پیشنهاد شغلی را بپذیرید یا رد کنید. درخت تصمیم این مسئله شبیه به شکل ۳ است. درخت تصمیم نشان میدهد که یک پیشنهاد شغلی باید پذیرفته شود، بهشرطی که حقوق بیشتر از 50000 هزار دلار داشته باشد، رفت و آمد کمتر از یک ساعت است و مشوقهایی ارائه میشود.
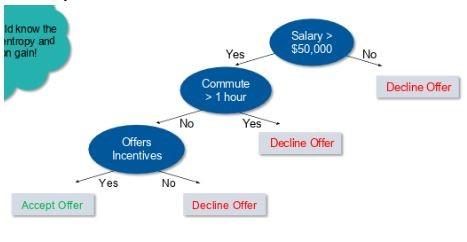
شکل 3
4. چگونه یک مدل جنگل تصادفی بسازیم؟
یک جنگل تصادفی از تعدادی درخت تصمیم تشکیل شده است. اگر دادهها را به بستههای مختلف تقسیم کنید و یک درخت تصمیم در هر یک از گروههای مختلف داده بسازید، جنگل تصادفی همه آن درختها را در کنار یکدیگر قرار میدهد. مراحل ساخت یک جنگل تصادفی بهشرح زیر است:
- بهطور تصادفی ویژگیهای k را از مجموع ویژگیهای m انتخاب کنید که k << m.
- در میان ویژگیهای k، گره D را با استفاده از بهترین نقطه تقسیم محاسبه کنید.
- با استفاده از بهترین مکانیزم تقسیم، گره را به گرههای قابل انشعاب، تقسیم کنید.
- مراحل ۲ و ۳ را تکرار کنید تا گرههای برگ نهایی شوند.
- با تکرار مراحل 1 تا 4 به تعداد n مرتبه برای n درخت، جنگل بسازید.
5. چگونه میتوانید از برازش بیشازحد مدل خود جلوگیری کنید؟
Overfitting یا همان برازش به مدلی اشاره دارد که فقط برای مقدار بسیار کمی داده تنظیم شده است و دورنمای بزرگتر دادهها را نادیده میگیرد. سه روش اصلی برای جلوگیری از مشکل برازش بیشازحد یک مدل وجود دارد.
- مدل را ساده نگه دارید. متغیرهای کمتری را در نظر بگیرید تا مقداری از نویز موجود در دادههای آموزشی حذف شود.
- از تکنیکهای اعتبارسنجی متقابل، مثل اعتبارسنجی متقاطع k folds استفاده کنید.
- از تکنیکهای منظمسازی مانند LASSO استفاده کنید که پارامترهای مدل را در صورت وجود احتمالات زیاد برازش، حذف میکنند.
مطلب پیشنهادی
 توسعه مدلهای هوشمند با اتکا بر مرورگرها
توسعه مدلهای هوشمند با اتکا بر مرورگرها
مطلب پیشنهادی
6. چه تفاوتی میان تحلیل تکمتغیره، دومتغیره و چندمتغیره وجود دارد؟
دادههای تکمتغیره فقط شامل یک متغیر هستند. هدف از تجزیهوتحلیل تکمتغیره توصیف دادهها و یافتن الگوهای موجود در آنها است. یک مثال رایج در این زمینه قد دانشآموزان است. برای دادههای تکمتغیره، الگوها را میتوان با نتیجهگیری و از طریق میانگین، میانه، حالت، پراکندگی یا محدوده، حداقل، حداکثر و غیره مطالعه کرد.
دادههای دومتغیره شامل دو متغیر متفاوت هستند. تجزیهوتحلیل این نوع دادهها به علل و روابط میپردازد، بهطوری که تجزیهوتحلیل برای تعیین رابطه بین دو متغیر انجام می شود. یک مثال رایج در این زمینه تاثیر متقابل افزایش دما بر مصرف انرژی است. در اینجا، دما و افزایش مصرف انرژی با یکدیگر نسبت مستقیم دارند. هرچه دما بیشتر باشد، مصرف انرژی بیشتر میشود. دادههای چندمتغیره شامل سه یا چند متغیر هستند که در زیرمجموعه چند متغیر دستهبندی میشوند. دادههای چندمتغیره شبیه به دومتغیره هستند، اما شامل بیش از یک متغیر وابسته هستند. یک مثال رایج در این زمینه خانه است که تعداد اتاقها، انباری، مساحت و تعداد طبقات بر قیمت آن تاثیرگذار هستند. برای شناسایی الگوها در این نوع متغیرها میتوان از میانگین، میانه، حالت، پراکندگی یا محدوده، حداقل، حداکثر و غیره استفاده کرد. بهطور مثال، میتوانید شروع به توصیف دادهها کنید و از آنها برای حدس زدن قیمت خانه استفاده کنید.
7. چه روشهایی برای انتخاب ویژگی برای متغیرها وجود دارد؟
دو روش اصلی برای انتخاب ویژگی وجود دارد که روشهای فیلتر و پوششدهنده (Wrapper) نام دارند. از روشهای فیلتر باید به تجزیهوتحلیل تشخیص خطی، ANOVA و Chi-Square اشاره کرد. از روشهای پوششدهنده باید به موارد زیر اشاره کرد:
- انتخاب روبهجلو: یک ویژگی را در یک زمان آزمایش میکنیم و بهتدریج ویژگیهای دیگر را اضافه میکنیم تا زمانی که به تناسب مدنظر برسیم.
- انتخاب روبهعقب: همه ویژگیها را آزمایش میکنیم و پس از آزمایش، شروع به حذف تک تک آنها میکنیم تا ببینیم کدامیک عملکرد بهتری دارند.
- حذف ویژگیهای بازگشتی: بهصورت بازگشتی، تمام ویژگیهای مختلف و نحوه جفت شدن آنها را با هم بررسی میکنیم.
بهطور مععمول روشهای Wrapper بیشتر مورد توجه قرار دارند. البته اگر قرار باشد تجزیهوتحلیل دادههای زیادی با روش wrapper انجام شود به سختافزار قدرتمندی نیاز است.
8. با استفاده از زبان برنامهنویسی که به آن مسلط هستید، برنامهای بنویسید که اعداد از یک تا 50 را چاپ کند، اما برنامه برای مضربی از سه بهجای عدد، واژه Fizz و برای مضرب پنج، Buzz را چاپ کند. برای اعدادی که مضرب سه و پنج هستند، FizzBuzz را چاپ کنید.
کد نشان دادهشده در شکل ۴ نحوه انجام اینکار را نشان میدهد. توجه داشته باشید که محدوده ذکرشده 51 است که بهمعنی ۰ تا 50 است. در هنگام کار با آرایهها و ساختارهای دادهای به این نکته دقت کنید که اندیس مکانی از ۰ و نه ۱، آغاز میشود.

شکل 4
9. مجموعه دادهای به شما داده میشود که متشکل از متغیرهایی است که بیش از 30 درصد، مقادیر ازدسترفته دارد. چگونه با چنین مجموعهای کار میکنید؟
دانشمندان داده از روشهای زیر برای مدیریت مقادیر دادههای از دست رفته استفاده میکنند:
- اگر مجموعه دادهها بزرگ است، میتوانیم بهسادگی ردیفهایی را که مقادیر دادههای گمشده دارند، حذف کنیم. این سریعترین راه است. در ادامه، از دادهها باقیمانده برای پیشبینی مقادیر استفاده میکنیم.
- برای مجموعه دادههای کوچکتر، میتوانیم مقادیر گمشده را با میانگین دادهها و با استفاده از فریم داده در پانداس جایگزین کنیم.
10. برای نقاط دادهشده، چگونه فاصله اقلیدسی را در پایتون محاسبه میکنید؟
plot1 = [1,3]
plot2 = [2,5]
فاصله اقلیدسی را میتوان بهصورت زیر محاسبه کرد:
euclidean_distance = sqrt( (plot1[0]-plot2[0])**2 + (plot1[1]-plot2[1])**2 )
11. کاهش ابعاد چیست و چه مزایایی دارد؟
کاهش ابعاد به فرآیند تبدیل یک مجموعه داده با ابعاد وسیع به دادههایی با ابعاد (فیلد) کمتر با هدف انتقال کمتر اطلاعات یکسان اشاره دارد. این کاهش به فشردهسازی دادهها و کاهش فضای ذخیرهسازی کمک میکند. همچنین، زمان محاسبات را کاهش میدهد، زیرا ابعاد به محاسبات کمتری نیاز دارند. علاوه بر این، کاهش ابعاد نقش مهمی در کاهش ویژگیهای اضافی دارد.
12. مقادیر ویژه و بردارهای ویژه ماتریس 3x3 زیر را چگونه محاسبه میکنید؟
| 2 | -4 | -2 |
| 2 | 1 | -2 |
| 5 | 2 | 4 |
معادله مورد نظر بههمراه مکانیزم تعیین بسطدهنده بهشرح زیر است:
(-2 – λ) [(1-λ) (5-λ)-2x2] + 4[(-2) x (5-λ) -4x2] + 2[(-2) x 2-4(1-λ)] =0
- λ3 + 4λ2 + 27λ – 90 = 0,
λ3 - 4 λ2 -27 λ + 90 = 0
در اینجا یک معادله جبری داریم که از بردارهای ویژه ساخته شده است. فرآیند جایگذاری و ضرب بهشرح زیر است:
33 – 4 x 32 - 27 x 3 +90 = 0
بنابراین، (λ - 3) یک عامل است:
λ3 - 4 λ2 - 27 λ +90 = (λ – 3) (λ2 – λ – 30)
مقادیر ویژه 3، -5 و 6 هستند:
(λ – 3) (λ2 – λ – 30) = (λ – 3) (λ+5) (λ-6),
اکنون بردار ویژه را برای λ = 3 محاسبه میکنیم:
For X = 1,
-5 - 4Y + 2Z =0,
-2 - 2Y + 2Z =0
تفریق دو معادله:
3 + 2Y = 0,
تفریق دوباره به معادله دوم:
Y = -(3/2)
Z = -(1/2)
به همین ترتیب، میتوانیم بردارهای ویژه را برای 5- و 6 محاسبه کنیم.
13. چگونه باید مدلی که استقرار یافته را نگهداری کنیم؟
مراحل نگهداری مدلی که استقرار یافته بهشرح زیر است:
- نظارت: نظارت مداوم بر همه مدلها برای تعیین دقت عملکرد آنها مورد نیاز است. وقتی چیزی را تغییر میدهید، دوست دارید ببینید تغییر شما چگونه روی دیگر عاملها تاثیرگذار خواهد بود. این فرآیند باید تحت نظارت انجام شود تا مطمئن شوید کارها بهدرستی انجام خواهند شد و نتیجه دلخواه بهدست خواهد آمد.
- ارزیابی: معیارهای ارزیابی برای تعیین اینکه آیا الگوریتم جدیدی مورد نیاز است یا خیر، انجام میشود.
- مقایسه: مدلهای جدید با یکدیگر مقایسه میشوند تا مشخص شود کدام مدل بهترین عملکرد را دارد.
- بازسازی: بهترین مدل بر مبنای دادههای فعلی و جدید مورد آزمایش قرار میگیرد تا عملکرد آن مشخص شود.
14. سیستمهای توصیهگر چیستند؟
یک سیستم توصیهگر پیشبینی میکند که کاربر بر اساس علاقهمندیهای خود، به یک محصول خاص چه امتیازی میدهد. سامانههای توصیهگر را میتوان به دو گروه اصلی تقسیم کرد:
فیلتر مشارکتی
بهعنوان مثال، Last.fm آهنگهایی را توصیه میکند که کاربران با علایق مشابه به آنها گوش میدهند. آمازون نیز در هنگام پیشنهاد محصولات از الگوی مشابهی استفاده میکند. برخی سایتهای فروش، هنگامی که کاربران اقدام به بازدید محصولاتی میکنند پیغام «کاربرانی که این محصول را خریدهاند و غیره» را نشان میدهند.
فیلتر مبتنی بر محتوا
پاندورا از ویژگیهای یک آهنگ برای توصیه آهنگهایی با ویژگیهای مشابه استفاده میکند. در اینجا، بهجای اینکه ببینیم چه کسی به موسیقی گوش داده به محتوا نگاه میکنیم.
15. چگونه RMSE و MSE را در مدل رگرسیون خطی پیدا کنیم؟
RMSE و MSE دو مورد از رایجترین معیارهای دقت برای مدل رگرسیون خطی هستند. RMSE خطای Root Mean Square را نشان میدهد.
r> rmse
[1] 3.339665e-11
MSE خطای میانگین مربع را نشان میدهد (شکل 5).

شکل 5
16. چگونه میتوانید k را برای k-means انتخاب کنید؟
ما از روش elbow برای انتخاب k در خوشهبندی k-means استفاده میکنیم. ایده بهکارگیری روش elbow این است که خوشهبندی k-means را روی مجموعه داده اجرا کنیم. در اینجا، k بیانگر تعداد خوشهها است. k در مجموع مربعها (WSS)، بهعنوان مجموع فاصله مجذور بین هر یک از اعضای خوشه و مرکز آن تعریف میشود.
17. چگونه میتوان مشکل مقادیر پرت را حل کرد؟
فقط در صورتی میتوانید مقادیر پرت (Outliers) را حذف کنید که مقادیر بدون استفاده باشند. اگر حذف مقادیر پرت بهسختی امکانپذیر است، ابتدا موارد زیر را آزمایش کنید.
یک مدل متفاوت را امتحان کنید. دادههای شناساییشده بهعنوان نقاط پرت توسط مدلهای خطی میتوانند با مدلهای غیرخطی برازش شوند. بنابراین، مطمئن شوید که مدل صحیح را انتخاب میکنید.
سعی کنید دادهها را نرمالسازی کنید. به این ترتیب، نقاط داده به یک محدوده مشخص اشاره خواهند داشت.
میتوانید از الگوریتمهایی استفاده کنید که کمتر تحت تاثیر عوامل پرت قرار میگیرند. یک مثال خوب در این زمینه جنگلهای تصادفی هستند.
18. چگونه میتوانید دقت را با استفاده از ماتریس درهمریختگی محاسبه کنید؟
ماتریس درهم ریختگی (Confusion Matrix) شکل ۶ را تصور کنید. فرمول محاسبه دقت بهشرح زیر است:
دقت = (مثبت واقعی + منفی واقعی) / کل مشاهدات
Accuracy = (True Positive + True Negative) / Total Observations
= (262 + 347) / 650
= 609 / 650
= 0.93
در مثال بالا، دقت 93 درصد است.
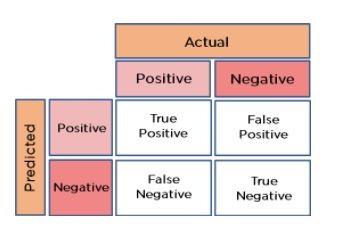
شکل 6
19. معادلهای بنویسید و دقت و نرخ فراخوانی را محاسبه کنید.
همان ماتریس درهمریختگی سوال قبل را در نظر بگیرید (شکل 7).

شکل 7
Precision = (True positive) / (True Positive + False Positive)
دقت = (مثبت واقعی) / (مثبت واقعی + مثبت کاذب)
=262 / 277
=0.94
Recall Rate = (True Positive) / (Total Positive + False Negative)
نرخ فراخوانی = (مثبت واقعی) / (مثبت کل + منفی کاذب)
=262 / 288
=0.90
20. توصیههایی که در آمازون مشاهده میشود، نتیجه کدام الگوریتم است؟
موتور توصیهگر که بر مبنای فیلتر مشارکتی کار میکند. فیلتر مشارکتی رفتار سایر کاربران و سابقه خرید آنها را از نظر رتبهبندی، انتخاب و غیره توضیح میدهد. این موتور بر اساس علاقهمندیهای دیگر کاربران، پیشبینیهایی را در مورد آنچه ممکن است مورد علاقه فرد دیگری باشد، انجام میدهد. در این الگوریتم، ویژگیهای یک عنصر ناشناخته است. بهعنوان مثال، یک صفحه فروش نشان میدهد که تعداد معینی از افراد یک گوشی جدید میخرند و همزمان شیشه محافظ گوشی نیز میخرند. دفعه بعد، وقتی شخصی گوشی میخرد، ممکن است توصیهای برای خرید شیشه محافظ به کاربر نشان داده شود.
21. یک پرسوجو ابتدایی SQL بنویسید که تمام سفارشات را با اطلاعات مشتری فهرست کند
بهطور معمول، ما جداول سفارش و جداول مشتری داریم که شامل ستونهای زیر است:
- جدول سفارش (Order Table)
- شماره سفارش (Orderid)
- شناسه مشتری (customerId)
- شماره سفارش (OrderNumber)
- مجموع کل (TotalAmount)
- جدول مشتری (Customer Table)
- شناسه (Id)
- نام کوچک (FirstName)
- نام خانوادگی (LastName)
- شهر (City)
- کشور (Country)
پرس و جوی SQL بر مبنای ستونهای فوق بهشرح زیر است:
SELECT OrderNumber, TotalAmount, FirstName, LastName, City, Country
FROM Order
JOIN Customer
ON Order.CustomerId = Customer.Id
22. مجموعه دادهای در مورد تشخیص سرطان به شما داده میشود. شما یک مدل طبقهبندی ساختهاید و به دقت 96 درصد دست یافتهاید. چه راهکاری برای ارزیابی عملکرد آن پیشنهاد میکنید؟
در موارد مرتبط با تشخیص با مشکل بزرگی روبهرو هستیم که عدم تعادل دادهها نام دارد. در یک مجموعه داده نامتعادل، دقت باید بهعنوان معیار عملکرد مورد توجه باشد و در نتیجه باید روی چهار درصد باقیمانده تمرکز کنیم که ممکن است بیانگر این موضوع باشند که تشخیص اشتباه انجام شده است. تشخیص زودهنگام در مواردی مثل سرطان بسیار مهم است و میتواند پیشآگهی بیمار را تا حد زیادی بهبود بخشد. از این رو، برای ارزیابی عملکرد مدل، باید از معیار حساسیت (Sensitivity) برای نرخ مثبت واقعی، ویژگی (Specificity) برای نرخ منفی واقعی و معیار F برای تعیین عملکرد طبقهبندیکننده استفاده کنیم.
23. کدامیک از الگوریتمهای یادگیری ماشین زیر را میتوان برای وارد کردن مقادیر ازدسترفته متغیرهای طبقهای و پیوسته استفاده کرد؟
- K-means clustering
- رگرسیون خطی
- K-NN (k- نزدیکترین همسایه)
- درختان تصمیم
میتوانیم از الگوریتم K نزدیکترین همسایه استفاده کنیم، زیرا میتواند فاصله نزدیکترین همسایه را محاسبه کند و اگر مقداری نداشته باشد، فاصله نزدیکترین همسایه را بر اساس ویژگیهای دیگر محاسبه میکند.
وقتی با K-means خوشهبندی یا رگرسیون خطی سروکار داریم، باید این کار را در پیشپردازش خود انجام دهیم، در غیر این صورت، محاسبهها با مشکل روبهرو میشوند. درختان تصمیم نیز در بیشتر موارد همین مشکل را دارند.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.






















نظر شما چیست؟