

یادگیری ماشین یکی از مهمترین ارکان حوزه روبهرشد علم داده است. با استفاده از روشهای آماری، الگوریتمها برای طبقهبندی یا پیشبینی آموزش میبینند و بینشهای کلیدی در پروژههای مبتنی بر دادهکاوی را آشکار میکنند.
بینشهایی که نقش مهمی در تصمیمگیریهای کلان تجاری و پیشبرد اهداف تجاری دارد. همانگونه که کلان دادهها به گسترش و رشد ادامه میدهند، تقاضای بازار برای دانشمندان داده افزایش مییابد. سازمانها از این متخصصان درخواست میکنند در شناسایی استراتژیهای تجاری و نحوه پیادهسازی به آنها کمک کنند. در شرایطی که اصطلاحاتی مثل یادگیری ماشین (با ناظر، بدون ناظر و تقویتی)، یادگیری عمیق، شبکههای عصبی و غیره تعاریف خود را دارند، گاهیاوقات مشاهده میکنیم که منابع یا کارشناسان از این اصطلاحات بهجای دیگری استفاده میکنند؛ بر همین اساس، در این مقاله به شما خواهیم گفت که هر یک از اصطلاحات مذکور چه تفاوتهایی با یکدیگر دارند.

یادگیری ماشین در مقابل یادگیری عمیق در مقابل شبکههای عصبی
از آنجایی که یادگیری عمیق و یادگیری ماشین بهجای یکدیگر مورد استفاده قرار میگیرند، مهم است تفاوتهای ظریف بین این دو اصطلاح را بدانیم. یادگیری ماشین، یادگیری عمیق و شبکههای عصبی همگی زیرشاخههای هوش مصنوعی هستند. با این حال، یادگیری عمیق در واقع زیرشاخهای از یادگیری ماشین است و شبکههای عصبی زیرمجموعه یادگیری عمیق هستند.
تفاوت یادگیری عمیق و یادگیری ماشین در نحوه یادگیری هر الگوریتم است. یادگیری عمیق بخش عمدهای از فرآیند استخراج ویژگیها را بهشکل خودکار انجام میدهد، تا حد امکان بدون نظارت مستقیم متخصصان کار میکند و استفاده از کلان دادهها را امکانپذیر میکند. لکس فریدمن در سخنرانی خود در موسسه MIT به نکته جالبی اشاره کرده و میگوید: «شما میتوانید یادگیری عمیق را بهعنوان یادگیری ماشین گسترشپذیر در نظر بگیرید. یادگیری ماشین کلاسیک یا غیرعمیق وابستگی بیشتری به انسانها برای یادگیری دارند. متخصصان مجموعهای از ویژگیها را برای درک تفاوت بین ورودیهای دادهای تعیین میکنند. در این مدل یادگیری به دادههای ساختاریافته برای آموزش بهتر مدل نیاز دارید».
یادگیری عمیق میتواند از مجموعه دادههای برچسبگذاریشده که بهعنوان یادگیری نظارتشده شناخته میشوند، برای دریافت اطلاعات دقیقتر استفاده کند، اما لزوما به یک مجموعه داده برچسبدار نیاز ندارد. این مدل یادگیری میتواند دادههای بدون ساختار را بهشکل خام (متن، تصاویر) دریافت کند و بهطور خودکار مجموعهای از ویژگیهایی را تعیین کند که دستههای مختلف دادهها را از یکدیگر متمایز میکند. برخلاف یادگیری ماشین، برای پردازش دادهها نیازی به مداخله انسانی ندارد و به ما امکان میدهد یادگیری ماشین را به روشهای جالبتری مقیاسبندی کنیم. یادگیری عمیق و شبکههای عصبی در درجه اول باعث تسریع پیشرفت در زمینههایی مانند بینایی کامپیوتر، پردازش زبان طبیعی و تشخیص گفتار میشوند.
در چند دهه گذشته که کامپیوترها توانایی پیادهسازی الگوریتمهای محاسباتی را بهدست آوردند، همسو با شبیهسازی رفتار محاسباتی مغز انسان، تحقیقات زیادی انجام گرفت که نتایج آن در شاخهای از علم هوش مصنوعی و در زیرشاخه هوش محاسباتی بهنام «شبکههای عصبی مصنوعی» ANNs سرنام Artificial Neural Networks خود را متجلی ساخت. بهطور معمول، شبکههای عصبی مصنوعی بر مبنای لایههای مختلفی اطلاعات را پردازش میکنند و میتوانند شامل یک لایه ورودی، یک یا چند لایه پنهان و یک لایه خروجی باشند. هر گره (سلول عصبی مصنوعی) به گره دیگری متصل میشود و وزن و آستانه خاص خود را دارد. اگر خروجی هر گره منفرد فراتر از مقدار آستانه تعیینشده باشد، آن گره فعال میشود و دادهها را به لایه بعدی شبکه ارسال میکند. در غیر این صورت، هیچ دادهای به لایه بعدی شبکه انتقال داده نمیشود. واژه عمیق (Deep) در یادگیری عمیق تنها به عمق لایهها اشاره دارد. یک شبکه عصبی که بیش از سه لایه دارد و ورودیها و خروجیهایی دارد، میتواند یک الگوریتم یادگیری عمیق یا یک شبکه عصبی عمیق در نظر گرفته شود. شبکه عصبیای که تنها دو یا سه لایه دارد، یک شبکه عصبی اولیه است.

یادگیری ماشین چگونه کار میکند
دانشگاه UC Berkeley مکانیزم یادگیری یک الگوریتم یادگیری ماشین را به سه بخش اصلی بهشرح زیر تقسیم میکند:
فرآیند تصمیمگیری: بهطور کلی، الگوریتمهای یادگیری ماشین برای پیشبینی یا طبقهبندی استفاده میشوند. بر اساس برخی از دادههای ورودی که میتوانند دارای برچسب یا بدون برچسب باشند، الگوریتم تخمینی در مورد یک الگوی مستتر در دادهها ارائه میکند.
تابع خطا: یک تابع خطا برای ارزیابی پیشبینی مدل بهکار میرود. اگر نمونههای شناختهشده وجود داشته باشد، یک تابع خطا میتواند مقایسهای برای ارزیابی دقت مدل انجام دهد.
فرآیند بهینهسازی مدل: اگر مدل بتواند بهشکل بهتری با نقاط دادهای در مجموعه آموزشی هماهنگ شود، وزنها بهگونهای طراز میشوند تا اختلاف میان مثالها و تخمین مدل کمتر شود. الگوریتم این فرآیند ارزیابی و بهینهسازی را تکرار میکند و وزنها را بهطور مستقل تا رسیدن به آستانه دقت بهروز میکند.

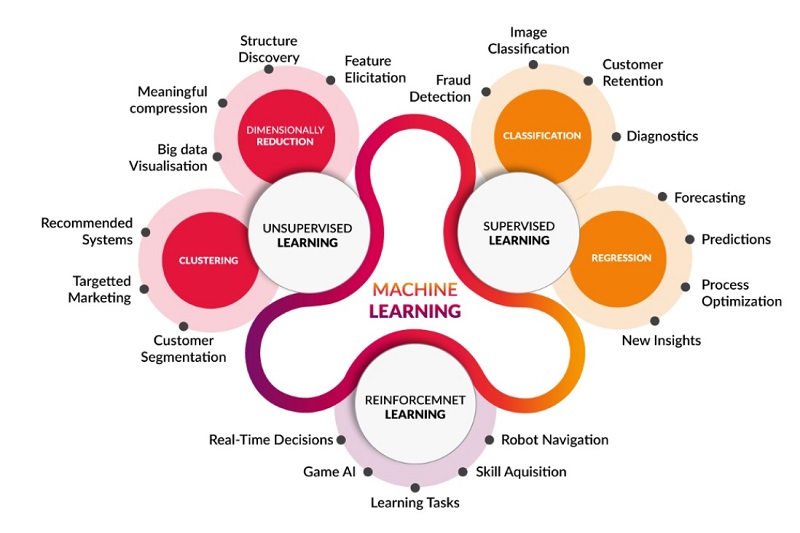
روشهای یادگیری ماشین
طبقهبندی پارادایمهای حاکم بر یادگیری ماشین به سه دسته اصلی زیر تقسیم میشوند:
یادگیری ماشین تحت نظارت/ با ناظر (Supervised machine learning)
یادگیری نظارتشده با استفاده از مجموعه دادههای برچسبگذاریشده برای آموزش الگوریتمهایی برای طبقهبندی دادهها یا پیشبینی دقیق نتایج تعریف میشود. به همان نسبتی که دادههای ورودی به مدل وارد میشود، وزن نیز تنظیم میشود تا زمانی که مدل بهطور درست برازش شود. رویکرد فوق بهعنوان بخشی از فرآیند اعتبارسنجی متقاطع انجام میشود تا اطمینان حاصل شود که مدل با مشکل برازش بیشازحد یا عدم تناسب روبهرو نمیشود. یادگیری تحت نظارت به سازمانها کمک میکند تا انواع مختلفی از مشکلات دنیای واقعی را در مقیاس بزرگ حل کنند که از مهمترین آنها باید به هدایت طبقهبندی هرزنامهها در یک پوشه جداگانه از صندوق ورودی ایمیل اشاره کرد. برخی از روشهای مورد استفاده در یادگیری نظارتشده عبارتند از: شبکههای عصبی، بیز ساده، رگرسیون خطی، رگرسیون لجستیک، جنگل تصادفی، ماشین بردار پشتیبان (SVM) و غیره. دو مرحله ساخت و آزمایش یک تابع نگاشت با یادگیری نظارتشده را در شکل ۱ مشاهده میکنید. الگوریتمهای مختلفی در زیر چتر یادگیری نظارتشده وجود دارند که ماشینهای بردار پشتیبان و بیز ساده از جمله آنها هستند.

شکل 1
یادگیری ماشین بدون نظارت (Unsupervised machine learning)
یادگیری بدون نظارت از الگوریتمهای یادگیری ماشین برای تجزیهوتحلیل و خوشهبندی مجموعه دادههای فاقد برچسب استفاده میکنند. این الگوریتمها الگوهای پنهان یا گروهبندی دادهها را بدون دخالت متخصصان کشف میکنند. الگوریتمهای مذکور توانایی کشف شباهتها و تفاوتها در اطلاعات با هدف ارائه راهحل ایدهآل برای تجزیهوتحلیل دادههای اکتشافی، استراتژیهای فروش متقابل، تقسیمبندی مشتریان، تشخیص تصویر و الگو را دارند. همچنین، برای کاهش تعداد ویژگیهای یک مدل از تکنیک کاهش ابعاد استفاده میکنند. تجزیهوتحلیل مولفه پایه (PCA) سرنام Principal Component Analysis و تجزیه ارزش منفرد (SVD) سرنام Singular Value Decomposition دو رویکرد رایج مورد استفاده توسط الگوریتمهای بدون نظارت هستند. از الگوریتمهای مطرح این حوزه باید به شبکههای عصبی، خوشهبندی k-means، روشهای خوشهبندی احتمالی و غیره اشاره کرد. شکل ۲ عملکرد فناوری فوق را نشان میدهد. میتوانید یادگیری بدون نظارت را با استفاده از الگوریتمهای مختلف، مانند خوشهبندی k-means، تئوری نوسان تطبیقی (Adaptive Resonance Theory)، یا نمونههای مشابه پیادهسازی کنید.

شکل 2
یادگیری نیمهنظارتی (Semi-Supervised Learning)
یادگیری نیمهنظارتی در مرز میان یادگیری تحت نظارت و بدون نظارت است. در مدل فوق، از یک مجموعه داده برچسبدار کوچک و مختصر برای کمک به مدل برای طبقهبندی و استخراج ویژگیها در یک مجموعه داده بزرگتر و بدون برچسب استفاده میشود. یادگیری نیمهنظارتی میتواند مشکل نداشتن دادههای برچسبگذاریشده کافی (یا عدم توانایی مالی برای برچسبگذاری دادههای کافی) را برای آموزش یک الگوریتم یادگیری نظارتشده حل کند.
مطلب پیشنهادی
 آشنایی با یکی از قدرتمندترین شاخههای هوش مصنوعی
آشنایی با یکی از قدرتمندترین شاخههای هوش مصنوعی
مطلب پیشنهادی
یادگیری ماشین تقویتی (Reinforcement Machine Learning)
یادگیری ماشین تقویتی یک مدل یادگیری ماشین رفتاری است که شبیه به یادگیری بدون نظارت است، اما الگوریتم با استفاده از دادههای نمونه (Samples) آموزش داده نمیشود. این مدل با استفاده از آزمونوخطا یاد میگیرد. در رویکرد فوق، مدل بر مبنای پاداش یا تنبیه یاد میگیرد که چگونه بهترین عملکرد را ارائه کند. بهطوریکه دنبالهای از نتایج موفقیتآمیز برای پیادهسازی بهترین توصیه یا خطمشی برای یک مشکل خاص مورد استفاده قرار میگیرند. سیستم واتسون آیبیام که برنده مسابقه تلویزیونی Jeopardy در سال 2011 میلادی شد، بهترین نمونه در این زمینه است. این سیستم از یادگیری تقویتی برای تصمیمگیری در مورد پاسخ دادن یا سؤال کردن استفاده کرد و توانست تشخیص دهد که کدام مربع را روی تخته انتخاب کند. لازم به توضیح است که یادگیری تقویتی خود دو گرایش به نامهای یادگیری تقویتی عمیق (Deep Reinforcement Learning) و فرا یادگیری تقویتی (Meta Reinforcement Learning) دارد. یادگیری تقویتی عمیق (Deep Reinforcement Learning)، از شبکههای عصبی عمیق برای حل مسائل یادگیری تقویتی استفاده میکند و به همین دلیل از واژه عمیق در آن استفاده شده است. Q-Learning که یادگیری تقویتی کلاسیک محسوب میشود و Deep Q-Learning که نمونه جدیدتری بهشمار میرود از گرایشهای مرتبط با این حوزه هستند. در رویکرد اول، از الگوریتمهای سنتی برای ساخت جدول Q استفاده میشود تا به عامل در پیدا کردن کاری که باید در هر وضعیت انجام شود کمک کرد. در رویکرد دوم، از شبکه عصبی (برای تخمین پاداش بر مبنای حالت: مقدار q) استفاده میشود. شکل ۳ مدل یادگیری تقویتی را نشان میدهد.

شکل 3
شبکههای عصبی (Neural networks)
شبکه عصبی یک بردار ورودی را بر مبنای مدلی الهامگرفته از نورونها و اتصال آنها در مغز پردازش میکند. این مدل از لایههایی از نورونها تشکیل شده که از طریق وزنهایی بههم متصل شدهاند که قادر به تشخیص اهمیت ورودیهای خاص هستند. هر نورون شامل یک تابع فعالساز است که خروجی نورون را تعیین میکند (بهعنوان تابعی از بردار ورودی آن ضرب در بردار وزن آن). خروجی با اعمال بردار ورودی به لایه ورودی شبکه و سپس محاسبه خروجیهای هر نورون از طریق شبکه (بهصورت پیشخور) محاسبه میشود. شکل ۴ لایههای یک شبکه عصبی عادی را نشان میدهد.

شکل 4
یکی از محبوبترین روشهای یادگیری تحت نظارت در ارتباط با شبکههای عصبی، پسانتشار (Back-Propagation) نامیده میشود. در پسانتشار، یک بردار ورودی برای تزریق دادهها و بردار خروجی برای محاسبه دارید. در الگوی فوق خطا محاسبه میشود (واقعی در مقابل دلخواه)، سپس برای تنظیم وزنها از لایه خروجی به لایه ورودی (بهعنوان تابعی از سهم آنها در خروجی، تنظیم نرخ یادگیری) دومرتبه منتشر میشود.
درخت تصمیم
درخت تصمیم یک روش یادگیری تحت نظارت قابل استفاده در طبقهبندی است که نتیجه یک بردار ورودی را بر اساس قوانین تصمیمگیری استنتاجشده از ویژگیهای موجود در دادهها ارائه میکند. درختان تصمیم مفید هستند، زیرا بهراحتی قابل تجسم هستند، بنابراین میتوانید عواملی را که زمینهساز تولید نتایج میشوند مشاهده کرده و درک کنید. شکل ۵ نمونهای از یک درخت تصمیمگیری رایج را نشان میدهد.
درختهای تصمیم به دو نوع اصلی تقسیم میشوند. درختهای طبقهبندی که در آن متغیر هدف یک مقدار گسسته است و برگها برچسبهای کلاس را نشان میدهند (همانطور که در درخت شکل ۵ نشان داده شده است) و درختهای رگرسیون که در آن متغیر هدف میتواند مقادیر پیوسته را دریافت کند. شما از یک مجموعه داده برای آموزش درخت استفاده میکنید و در ادامه یک مدل از دادهها ایجاد میکنید. سپس، میتوانید از درخت برای تصمیمگیری در ارتباط با دادههای دیدهنشده استفاده کنید.

شکل 5
الگوریتمهای مختلفی در ارتباط با یادگیری درخت تصمیم وجود دارند. یکی از گزینههای مهم در این زمینه ID3 سرنام Dichotomiser 3 است که با تقسیم مجموعه دادهها به دو مجموعه داده جداگانه بر اساس یک فیلد واحد در بردار کار میکند. شما این فیلد را با محاسبه آنتروپی آن (معیار توزیع مقادیر آن فیلد) انتخاب میکنید. هدف انتخاب فیلدی از بردار است که منجر به کاهش آنتروپی در تقسیمات بعدی مجموعه داده در حین ساخت درخت میشود. از دیگر الگوریتمها در این زمینه باید به Beyond ID3 الگوریتم بهبودیافته و جایگزین ID3 که C4.5 نام دارد و الگوریتم MARS سرنام Multivariate Adaptive Regression Splines اشاره کرد که درختهای تصمیم را با مدیریت دادههای عددی بهبودیافته میسازند.
کلام آخر
یادگیری ماشین متشکل از طیف گستردهای از الگوریتمها است که متناسب با نیازهای یک پروژه قابل استفاده هستند. الگوریتمهای یادگیری نظارتشده یک تابع نگاشت را برای یک مجموعه داده با طبقهبندی موجود میآموزند که در آن الگوریتمهای یادگیری بدون نظارت میتوانند مجموعه دادههای بدون برچسب را بر اساس برخی ویژگیهای پنهان در دادهها دستهبندی کنند. در نهایت، یادگیری تقویتی میتواند خطمشیهایی را برای تصمیمگیری در یک محیط نامشخص از طریق مکانیزم کاوش مداوم در آن محیط بیاموزد.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.






















نظر شما چیست؟