


مطلب پیشنهادی
 وظایف اصلی یک مهندس هوش مصنوعی
وظایف اصلی یک مهندس هوش مصنوعی
مطلب پیشنهادی
DataRobot چیست؟
DataRobot مبتنی بر الگوریتمهای منبعباز است و از سرویسهای آمادهبهکار هوش مصنوعی برای ارائه ویژگیهایی که برای ساخت و استقرار مدلهای یادگیری ماشین در دسترس هستند، استفاده میکند.
DataRobot یک پلتفرم پیشرفته هوش مصنوعی تجاری است که علم داده را دموکراتیزه میکند و فرآیند پایان طراحی، پیادهسازی و استقرار الگوریتمهای هوشمند را خودکارسازی میکند. DataRobot از جدیدترین الگوریتمهای منبع باز پشتیبانی میکند و ابرمحور است، این توانایی را دارد تا از طریق ابر، یک سرویس درون سازمانی یا بهعنوان یک سرویس هوش مصنوعی کامل که قابلیت مدیریت توسعهدهندگان را دارد مورد استفاده قرار گیرد. در همه موارد، کاربران یا شرکتها میتوانند از قدرت هوش مصنوعی برای دستیابی به نتایج تجاری کارآمد استفاده کنند. در این مقاله، نحوه ساخت یک مدل طبقهبندیکننده یادگیری ماشین بر مبنای DataRobot را یاد خواهیم گرفت.
در این مقاله از دادههای مربوط به کمپین بازاریابی یک موسسه بانکی استفاده میکنیم که مبتنی بر تماسهای تلفنی انجامشده در ارتباط با فعالیتهای بازاریابی است. اغلب برای تعیین این که آیا سپردهگذاری یا به عبارت دقیقتر مشتری بانک، دوست دارد تا سپرده مدتداری در بانک ایجاد کند یا خیر با او تماس گرفته میشود. ما قصد داریم یک مدل طبقهبندی را ایجاد کنیم تا به بررسی این موضوع بپردازیم که آیا باید با مشتریان تماسی برقرار کنیم یا خیر. به بیان دقیقتر، هوش مصنوعی به ما پیشنهاد خواهد داد با چه مشتریانی تماس برقرار کنیم.
ابتدا کار را با آپلود دادهها شروع میکنیم، زیرا مدل بدون داده نمیتواند چیزی یاد بگیرد.
آپلود دادهها
- پس از ثبتنام و ورود به صفحه وب DataRobot، صفحهای وجود دارد که از گزینههایی مانند تجسم دادهها، ساخت مدل هوش مصنوعی و استقرار سوالاتی را مطرح میکند. پس از انتخاب صفحه موردنظر به چیزی شبیه به صفحه زیر هدایت میشوید.


نکتهای که قبل استفاده از سرویس فوق باید به آن دقت کنید این است که شرایط خاصی برای استفاده از دادهها به شرح زیر وجود دارد:
- باید از فرمت فایلی صحیح استفاده کنید.
- حجم مجموعه دادهها کمتر از 200 مگابایت باشد.
- حداقل 20 ردیف داشته باشد.
- نباید بیش از یک سرصفحه ستون ازدسترفته وجود داشته باشد.
- امکان استفاده از سرصفحه ستون تکراری وجود ندارد.
- نباید از بدون رمزگذاری پشتیبانینشده یا متناقض استفاده شود.
اگر فایل داده شما بیشتر از 200 مگابایت است، باید یک شناسه شغلی ایجاد کنید تا بتوانید از آن استفاده کرد، زیرا DataRobot بارگذاری مستقیم را به 200 مگابایت محدود کرده است.
در ادامه روی Data در نوار وظیفه بالای صفحه وب کلیک کنید تا به دادهها دسترسی پیدا کنید. پس از بارگذاری دادهها، ستون هدف باید انتخاب شود. اگر ستون هدف گسسته است، DataRobot یک نمودار شمارش برای دستهها ایجاد میکند.

انتخاب مدل
- پس از انتخاب ستون هدف باید به سراغ حالت مدلسازی بروید. در این زمینه، حالتهای مختلفی وجود دارد که بهصورت quick، autopilot، manual و comprehensive وجود دارد.
- حالت quick یک حالت آغازکننده است که مدلهای پایه تولید میکند و امکان انجام تنظیمات اولیه را فراهم میکند.
- حالت autopilot تمام مدلهای ممکن ارائهشده توسط DataRobot را در تعامل با اعتبارسنجی متقابل، آموزشهای آزمایشی ساده و انتخاب ویژگیها ایجاد میکند.
- حالت manual یک حالت تعریفشده توسط کاربر است که به این معنا است که شما میتوانید مدل را به تنهایی انتخاب کنید و بر اساس به آموزش آن بپردازید.
- حالت comprehensive یک گام فراتر از حالت autopilot است. اگر مدل autopilot مناسب کاری نیست که انجام میدهید، میتوانید از حالت فوق استفاده کنید.
مطلب پیشنهادی

در ادامه قصد داریم حالت autopilot را بررسی کنیم.
پس از انتخاب گزینه فوق، تنها روی دکمه شروع کلیک کنید تا صفحهای همانند حالت زیر را مشاهده کنید.

- در اینجا دادهها تجزیهوتحلیل میشوند و در ادامه، میتوانید تعداد ویژگیهایی را که برای هدف آموزشی استفاده میشوند انتخاب کنید. پس از اتمام کار با این بخش، میتوانید با کلیک بر روی Models به انتخاب مدلها یا بسته به حالتی که قبلا در بخش Modeling انتخاب شده است، بروید.
- از آنجایی که ما از حالت autopilot استفاده میکنیم، پس از تکمیل بخش تجزیهوتحلیل دادهها، این مدل به طور خودکار مقداردهی اولیه میشود. بنابراین، ما فقط باید بنشینیم و منتظر تکمیل فرآیند باشیم.
محاسبه نتایج
- این فرآیند با 31 مدل راهاندازی میشود. این 31 مدل نسخههای مختلف مدل پایه هستند. مدل پایه که در آن طبقهبندیکنندههای مبتنی بر درخت و طبقهبندیکنندههای خطی اعمال شده است.

- در نهایت، در مجموع 63 مدل با اندازه نمونههای مختلف، ترکیب الگوریتمهای مختلف مبتنی بر درخت و الگوریتمهای خطی، تنظیم فراپارامترهای مختلف و غیره در دسترس قرار میگیرند.

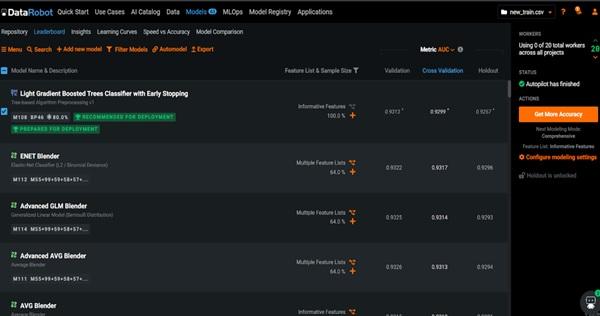
- پس از تکمیل، حالت autopilot توصیه میکند که Light Gradient Boosted Trees Classifier with Early Stopping را استفاده کنید.
- اکنون فوق آن رسیده تا عملکرد مدل نهایی را بررسی کنیم. با کلیک بر روی نام مدل میتوانیم پارامترهای مختلفی را مشاهده کنیم که براز ارزیابی عملکرد مدل در دسترس قرار دارند. این پارامترها کمک میکنند تا دلیل استفاده از گزینه مذکور را بهتر درک کنید.

- در پنل سمت راست مشاهده میکنیم که یک ماتریس confusion وجود دارد و در زیر آن، حساسیت و دقت را داریم که دقت 0.52 و حساسیت 0.70 است. برای این مقاله، ما نرخ مقادیر پیشبینیشده مثبت را در نظر میگیریم تا این مشتریان توسط تیم فروش انتخاب شوند. در پانل سمت چپ، میتوانیم منحنی ROC و امتیاز AUC 0.92 را مشاهده کنیم که نشان میدهد، این مدل عملکرد خوبی دارد.
- برای روشن شدن بحث، اجازه دهید زمان پردازش را تحلیل کنیم، زیرا هنگام استقرار یک مدل موضوعی که مهم است این است که مدل با چه سرعتی میتواند ورودیهای کاربر را پردازش کند. یک مدل سریعتر با عملکرد پایین در پیشبینی بهتر از یک مدل کندتر با عملکرد بالا است.
- اگر بر روی زبانه Speed vs Accuracy کلیک کنید، نمودار پراکندگی عملکرد با زمان را مشاهده میکنید.

- مدل نهایی بهترین است، زیرا سریعترین مدلی است که تنها 67.1 میلی ثانیه زمان برای پردازش دادهها سپری کرده است. به نظر میرسد، پیشنهادی که حالت autopilot ارائه کرده موثر واقع شده است. اکنون زمان آن رسیده تا فرآیند استقرار مدل را بررسی کنیم.
مدل نهایی را مستقر کنید
- استقرار مدل آسان است، فقط با کلیک بر روی کادر کنار نام مدل، مدل را از تب Models انتخاب میکنیم. سپس بر روی دکمه "deploy" کلیک میکنیم و مدل مستقر میشود.
- پس از استقرار مدل، میتوانید با کلیک بر روی زبانه «ML Ops» در بالای نوار وظیفه، مدل را مشاهده کنید.

کلام آخر
DataRobot میتواند با وارد کردن یک فایل، پیشبینیها را یکی یکی یا در دسته های بزرگ ایجاد کند.
هر مدل یادگیری ماشین را میتوان با استفاده از DataRobot به یک برنامه هوش مصنوعی بالقوه تبدیل کرد و به هر کسی در اکوسیستم اجازه داد با بینش پیشبینیکننده مدل اصلی تعامل داشته باشد. این سرویس کاربردی به شما امکان میدهد یک پیشبینی را با نتایج تاریخی مقایسه کنید، دلایل پیشبینی را بررسی کنید، و پارامترهای ورودی را تغییر دهید تا ببینید چگونه بر این نتایج تأثیر میگذارد. در مجموع در مقاله فوق، سعی کردیم ساخت و استقرار یک مدل پیشگویانه را با استفاده از DataRobot به شما نشان دهیم.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.





















نظر شما چیست؟