

نگاشت کاهش چیست؟
نگاشت کاهش(MapReduce) یک چارچوب نرمافزاری است که توسط گوگل برای پشتیبانی از رایانش توزیعشده ارائه شده است. این رایانش روی مجموعههای داده که متشکل از کلاسترهای کامپیوتری است، استفاده میشود. به بیان دقیقتر، نگاشتکاهش چارچوبی برای پردازش مجموعههای عظیمی از دادهها روی (گرهها) است که روی موضوعی خاص فعالیت میکنند. این مجموعه روی هم رفته به عنوان خوشه شناخته میشود. پردازش محاسباتی روی دادهای ذخیره شده درون سامانه فایل (ساختار نیافته) یا روی پایگاه داده (ساختاریافته) قابل اجراست.
هدوپ قدرت بلامنازع در دنیای مدیریت بزرگ دادهها
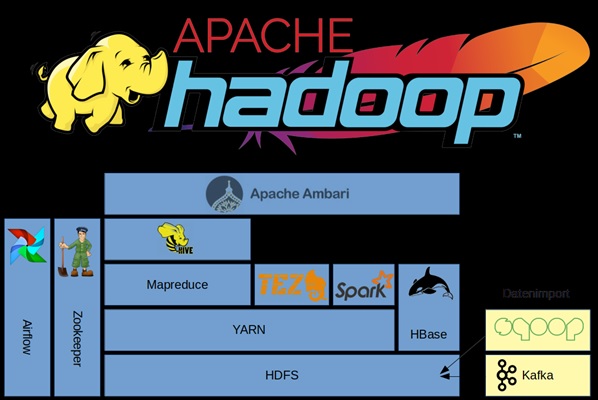
هدوپ یک پروژه سطح بالای آپاچی است که توسط گستره وسیعی از مشارکتکنندگان پشتیبانی و استفاده میشود و از زبان برنامهسازی جاوا استفاده میکند. بسته مشترکات هدوپ شامل فایلهای اجرایی تولید شده توسط مترجم جاوا و اسکریپتهایی است که برای راهاندازی هدوپ ضروری هستند. علاوه بر این، بسته فوق شامل کد منبع، مستندات و بخشی برای همکاری با پروژههای جامعه هدوپ است. خصوصیت کلیدی برای زمانبندی مؤثر کار، آن است که هر پرونده سیستمی باید مکان خود را اعلان کند: نام رَک (به صورت دقیقتر سوییچ شبکه) همان جایی که گره کارگر قرار دارد. برنامه کاربردی هدوپ از این اطلاعات برای اجرای کار روی گرههایی که دادهها در آنها قرار دارد (و در صورت عدم امکان روی همان رک یا سوئیچ) استفاده میکنند و بدین ترتیب از ترافیک در ستون فقرات شبکه میکاهند. فایلهای سیستمی اچدیافاس از این روش برای ایجاد نسخ مختلفی از یک داده روی رکهای متفاوت استفاده مینماید. هدف این است که فشار روی یک رک یا خطای سوئیچ کاهش پیدا کند تا حتی در صورت رخداد چنین حوادثی، داده کماکان قابل خواندن باشد. یک خوشه کوچک هدوپ شامل یک گره ارباب و چندین گره کارگر میباشد. گره ارباب از یک دنبالکننده کار (Jobtracker)، دنبالکننده وظیفه (Tasktracker)، گره نام (NameNode) و گره داده (DataNode)، و گره کارگر از یک گره داده و یک دنبالکننده وظیفه تشکیل شدهاند. گرههای کارگر همچنین میتوانند تنها شامل داده یا تنها محاسباتی باشند. هدوپ برای اجرا نیاز به نسخه JRE 1.6 یا بالاتر دارد و برای شروع و پایان استاندارد اسکریپتها و ارتباط بین گرهها در خوشه وجود پوسته امن الزامی است.
فایل سیستم توزیعشده هدوپ
اچدیافاس (Hadoop Distributed File System) یک فایل سیستم توزیعشده، قابلگسترش و قابلحمل است که در جاوا نوشته شده. هر گره در یک نمونه هدوپ تنها یک گره داده دارد. هر گره داده با استفاده از یک پروتکل بلاک خاص اچدیافاس بلاکهایی از داده را در سرتاسر شبکه در اختیار میگذارد. این فایل سیستمی برای برقراری ارتباط از لایه مجموعه پروتکل اینترنت استفاده میکند و کارگزارها (client) برای گفتگو با هم از RPC استفاده میکنند. اچدیافاس فایلهای بزرگ (اندازه مناسب برای یک فایل ضریبی از ۶۴ مگابایت است.) را در چندین ماشین ذخیره نموده و با تکرار کردن یک داده روی هاستهای متفاوت قابلیت اطمینان را افزایش میدهد؛ و به همین دلیل نیازی به ذخیرهسازی آرایه چندگانه دیسکهای مستقل روی هاستها ندارد. به صورت پیشفرض، داده روی سه گره، دو بار روی رک یکسان و یک بار روی رکی متفاوت ذخیره میشود. همچنین گرههای داده میتوانند با هم برای مواردی از قبیل متوازنسازی دادهها، انتقال کپیها، و بالا نگه داشتن تعداد نسخ صحبت کنند. اچدیافاس چندان تابع پازیکس نیست، زیرا اصولاً اهداف یک فایل سیستمی POSIX با اهدافی که هدوپ دنبال میکند، متفاوت است؛ که نتیجهٔ این امر، کارایی بالا برای گذردهی دادههاست و اچدیافاس نه به هدف فراهم کردن دسترسپذیری بالا، بلکه برای پاسخگویی به فایلهای بسیار بزرگ طراحی شدهاست.
یک نمونه فایل سیستمی اچدیافاس به یک سرور منحصربهفرد، یعنی همان گره نام احتیاج دارد که تنها نقطه خطای سیستم است. به این معنی که اگر گره نام با مشکل مواجه شود، فایل سیستمی قابلاستفاده نخواهد بود و هرگاه دوباره برگردد، گره نام میبایست تمام عملیات ثبتنشده را تکرار کند. این فرایند تکرار ممکن است بیش از نیم ساعت برای یک خوشه بزرگ به طول انجامد. این فایل سیستمی دارای یک گره نام ثانویهاست که بسیاری را به این تصور اشتباه میاندازد که زمانی که گره نام اصلی از کار بیفتد، گره نام ثانویه جای آن را خواهد گرفت. در حقیقت، گره نام ثانویه مرتباً به گره نام اصلی وصل میشود و تصاویری لحظهای از اطلاعات دایرکتوری آن گرفته و در دایرکتوریهای محلی یا دوردست ذخیره میکند. این تصاویر میتوانند برای راهاندازی مجدد یک گره نام اصلی که دچار خطا شده مورد استفاده قرار گیرند، بدون این که نیاز باشد تمام عملیات فایل سیستمی دوباره تکرار شود.
یک مزیت استفاده از فایل سیستمی اچدیافاس آگاهی از دادهها بین دنبالکننده کار و دنبالکننده وظیفه است. دنبالکننده کار، کارهای نگاشت/کاهش دنبالکننده وظیفه را با آگاهی از محل دادهها مدیریت میکند. فرض کنیم گره A شامل داده (x,y،z) و گره B شامل داده (a,b،c) باشد. دنبالکننده کار به این طریق مدیریت میکند که گره B را مسئول انجام کارهای نگاشت/کاهش روی (a,b،c) و گره A را موظف به انجام نگاشت/کاهشهای روی (x,y،z) میکند. بدینترتیب، حجم ترافیک روی شبکه کاهش پیدا میکند و از انتقال غیرضروری دادهها ممانعت به عمل میآید؛ که تأثیر قابلتوجهی روی بهبود زمان اتمام کارها دارد. شایان ذکر است زمانی که هدوپ روی فایل سیستمهای دیگر اجرا میشود، این مزیت همیشه وجود ندارد.
هدوپ میتواند مستقیماً با هر فایل سیستمی توزیعشدهای که قابلیت نصب شدن روی سیستمهای عامل سازگار را داشتهباشد، به-آسانی با استفاده از یک آدرس //:file کار کند. هرچند که این با پرداخت هزینهای صورت میگیرد: از دست رفتن محلیت. برای کاهش دادن ترافیک شبکه، هدوپ باید بداند که کدام سرور به داده نزدیکتر است و این اطلاعاتی است که فایل سیستم خاص هدوپ میتواند فراهم کند.
دنبالکننده کار و دنبالکننده وظیفه: موتور نگاشت/کاهش
بعد از فایلهای سیستمی، موتور نگاشت/کاهش قرار دارد که از یک دنبالکننده کار تشکیل شده که برنامههای کارگزار روی آن کارهای نگاشت/کاهش را ثبت میکنند. این دنبالکننده کار، کار را به گرههای دنبالکننده وظیفه در دسترس خوشه میدهد و تلاش میکند کار را تا حد امکان نزدیک داده نگه دارد. با یک فایل سیستم آگاه از رک، دنبالکننده وظیفه میداند که هر گره چه دادههایی را شامل میشود و چه ماشینهای دیگری در نزدیکی هستند. اگر امکان این وجود نداشته باشد که کار روی همان گرهای که شامل دادهاست، انجام شود، اولویت به گرههایی داده میشود که روی همان رک هستند. اگر یک دنبالکننده وظیفه دچار خطا شود یا زمانش تمام شود، آن بخش از کار دوباره زمانبندی میگردد. دنبالکننده وظیفه روی هر گره، یک پردازه جدای ماشین مجازی جاوا تولید میکند تا خود دنبالکننده وظیفه در صورت مشکلدار بودن کار در حال اجرا، از خطا مصون بماند. هر چند دقیقه یک ضربان از سوی دنبالکننده وظیفه به دنبالکننده کار فرستاده میشود تا وضعیتش بررسی شود. وضعیت و اطلاعات این دو دنبالکننده به وسیله بلنداسکله نمایش داده میشود و از طریق یک مرورگر وب میتوان آن را مشاهده کرد.
در نسخه هدوپ ۰٫۲۰ یا پایینتر، اگر دنبالکننده کار دچار خطا میشد، تمام کار در حال پیشرفت از دست میرفت. نسخه ۰٫۲۱ هدوپ تعدادی نقطه بررسی به این فرایند اضافه کرد. به این صورت که دنبالکنندهٔ کار، کاری که تا آن لحظه انجام داده را در فایل سیستمی ذخیره میکند. زمانی که یک دنبالکننده کار آغاز به کار میکند، به دنبال هر گونه از چنین دادهای میگردد و کار را از همان جایی که قبلاً رها کرده بود شروع میکند.
فایل سیستمی اچدیافاس محدود به کارهای نگاشت/کاهش نمیشود. بلکه میتواند برای برنامههای دیگر بسیاری که در آپاچی در حال اجرا و توسعه هستند، از قبیل پایگاه داده HBase، سیستم یادگیری ماشینی Mahout آپاچی، و سیستم انباره داده Hive آپاچی مورد استفاده قرار گیرند. هدوپ در واقع میتواند برای هر گونه کار که بیش از real-time بودن، batch-oriented باشد، استفاده شود و قادر است با بخشهایی از داده به صورت موازی کار کند. بهطور مثال در اکتبر ۲۰۰۹، برنامههای تجاری هدوپ عبارت بودند از ثبت وقایع و تحلیل کلیکاستریم به انواع مختلف، تحلیلهای بازاریابی (Marketing Analytics)، یادگیری ماشینی و/یا استخراج دادههای پیچیده، پردازش تصویری، پردازش پیامهای XML، خزندگی وب (Web Crawling) و/یا پردازش متن و بایگانی عمومی (General Archiving) شامل دادههای رابطهای و جدولی بودند.
نگاه دقیقتری به نگاشت
گاشتکاهش چارچوبی برای پردازش مجموعههای عظیمی از دادهها بر روی رایانهها(گرهها) که بر روی موضوعی خاص فعالیت میکنند. این مجموعه رویهم رفته به عنوان خوشه شناخته میشود(در صورتی که از سختافزاری یکسان بهره برند). پردازش محاسباتی بر روی دادهایِ ذخیره شده درون سامانه فایل (ساختار نیافته) یا بر روی پایگاه داده (ساختاریافته) قابل اجراست. نگاشت گره اصلی (Master Node) ورودی را به قطعاتی کوچکتر تقسیم میکند و سپس تقسیم این مسایل کوچک بین گرههای کارگر را مدیریت میکند. یک گره کارگر نیز ممکن است این عملیات را به نوبه خود تکرار نماید، که ایجادکنندهای ساختاری درختی و چند مرحلهای است. هر گره کارگر زیر-مسئله خود را حل نموده و نتیجه را به گره اصلیِ خود برمیگرداند. گامِ کاهش، سپس گرهِ اصلی جواب زیر-مسایل را از گرههای کارگرش گرفته و خروجی را میسازد تا خروجی، که حل مسئله ورودی است، را ایجاد نماید.
برتری نگاشتکاهش، در این است که اجازه میدهد تا پردازش عملیات پردازش و کاهش توزیعشود. فراهم آوردن این امر که هر کدام از این نگاشتها مستقل از دیگران است، که خود متضمن اجرای موازی این نگاشتهاست. اگرچه این گفته در عمل به این صورت خواهد بود که محدود به منابع داده یا تعداد پردازندههای نزدیک به آن دادهاست. به صورت مشابه، مجموعهای از 'کاهندهها' میتوانند فاز کاهش را به انجام رسانند. لازمه این امر آن است که خروجی عملیات نگاشت کلیدی یکسان را در یک زمان به همه کاهندهها ارسال نماید. این روش برای الگوریتمهایی که به صورت دنبالهای از دستورهای غیرقابل موازی سازی هستند، ناکارآمد است. نگاشتکاهش بر روی مجموعههای عظیم دادهای بهتر جواب میدهد تا سرورهای تجاری. مجموعههای عظیم دادهای را میتوان به مزارع سرور تعمیم داد. مزارعی که حجمی به بزرگی چندین پتابایت داده را در کسری از ساعت، پردازش مینماید. همچنین موازیسازی امکان بازسازی بعد از بروز خطایِ جزئی در سرورها را در طول عملیات فراهم میآورد: اگر یکی از نگاشتکنندگان یا کاهندگان دچار خطا شود، کار دوباره زمانبندی خواهدشد- با فرض اینکه داده همچنان در دسترس باشد.
آپاچی تریفت
تریفت یک زبان توصیف واسط و پروتکل دودویی است که برای تعریف و ایجاد سرویسها برای زبانهای بسیاری مورد استفاده قرار میگیرد. تریفت یک چارچوب تماس با روش از راه دور (RPC) شکل میدهد که در شرکت فیسبوک برای «توسعه سرویسهای چند زبانه مقیاس پذیر» توسعه یافتهاست. این نرمافزار یک پشته راه حل را با یک موتور تولید کد ترکیب میکند تا سرویسهای چندسکویی که میتوانند برنامههای نوشته شده با زبانها و چارچوب نرمافزاری متفاوت را به هم متصل کنند، ار جمله اکشناسکریپت، سی، سیپلاسپلاس، سی شارپ، کاپوچینو، کوکو، دلفی، ارلنگ، گو، هسکل، جاوا، جاوا اسکریپت، آبجکتیو-سی، اکمل، پرل، پیاچپی، پایتون، روبی، الیکسیر، راست، اسمالتاک، سوئیفت.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.






















نظر شما چیست؟