


هرچند شبکههای عصبی نقش مهمی در حوزه یادگیری عمیق دارند و استفاده از آنها در سالهای اخیر گسترش زیادی یافته، اما هنوز درک درستی از آنها نداریم. محققان از آنها استفاده میکنند بدون اینکه به درستی بدانند این سامانهها چگونه و چرا کار میکنند! گروهی از محققان اِمآیتی سعی کردهاند پاسخی مناسب برای این پرسش بیابند و در این راه، به نتایج جالب توجهی رسیدهاند. شبکههای عصبی که استفاده میکنیم بیش از آنچه که نیاز داریم بزرگ هستند. در برخی موارد آنها ده و حتی صد برابر بزرگتر از نیاز ما هستند و در نتیجه برای آموزش دادن آنها، بخش زیادی از توان محاسباتی و زمانمان به هدر میرود. به بیان دیگر ساختار یک شبکه عصبی را میتوان چنان ساده کرد که تأثیری روی عملکرد آن نداشته باشد، اما در وقت و هزینه پردازشی صرفهجویی شود. نتایج مطالعه محققان اِمآیتی نشان داد شبکههایی که آموزش میدهیم زیرشبکهای دارند که بهتر و غالباً سریعتر آموزش میبینند.
ساختار شبکههای عصبی
شبکههای عصبی از واحدهای محاسباتی سادهای تشکیل شدهاند که به هم متصل میشوند تا بتوانند الگوهای درون دادهها را بیابند .
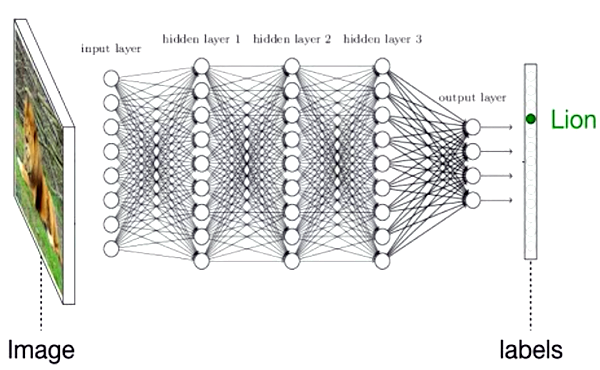
شکل۱- نموداری از یک شبکه عصبی. شبکههای عصبی ساختاری لایهای متشکل از گرههای ساده پردازشی هستند که بر اساس آنچه آموزش دیدهاند با هم در ارتباطاند.
در این ساختار، اتصالات نقش مهمی دارند. پیش از آغاز فرایند آموزش شبکه، مقادیری تصادفی بین صفر تا یک به این اتصالات اختصاص داده میشود که این مقادیر، اهمیت یا وزن هر اتصال را نشان میدهند. در مرحله آموزش، مجموعهای از دادهها به این ساختار اولیه خورانده میشود و شبکه بر اساس این دادههای آموزشی، وزن اتصالات خود را به تدریج تصحیح میکند بطوریکه برخی اتصالات تقویت شده و برخی تضعیف میشوند و بدین ترتیب ساختار نهایی شبکه شکل میگیرد؛ این رویکرد مشابه همان فرایندی است که در مغز و در جریان دانشاندوزی و تجربه کردن اتفاق میافتد. پس از اتمام آموزش یعنی نهایی شدن مقادیر اتصالات، شبکه آماده است که با دریافت داده ورودی (مثلاً عکس یک جانور)، خروجی مورد نظر (نام جانور) را تحویل دهد. اینکه شبکههای عصبی چگونه اینکار را میکنند هنوز در حد یک راز باقی مانده است! با این حال با جمعبندی مطالعات صورت گرفته میتوان به دو خصوصیت مهم و مفید شبکههای عصبی پی برد.
نخست اینکه همیشه این احتمال وجود دارد مقادیر اولیه اتصالات، شبکه را به جایی ببرند که پیکربندی حاصل، قادر به آموختن نباشد. در این صورت این پیکربندی اولیه از همان آغاز شکست خورده و دیگر مهم نیست برای آموزش دادن آن، چه حجمی از داده آموزشی و توان پردازشی استفاده شود؛ دادههای آموزشی بیشتر، تأثیری بر عملکرد شبکه نخواهند داشت. در این حالت شما مجبورید شبکه را بار دیگر با مقادیر تصادفی جدید مقداردهی کنید تا شاید این بار به پیکربندی بهتری دست یابید که آمادگی بیشتری برای آموختن داشته باشد. به نظر میرسد در شبکههای بزرگتری که لایهها و گرههای بیشتری دارند، احتمال بروز چنین مشکلی کمتر است. بهطور مثال، ممکن است برای یک شبکه عصبی کوچک، از هر پنج پیکربندی فقط یک پیکربندی توانایی آموختن داشته باشد، حال آنکه در یک شبکه بزرگتر، از هر پنج پیکربندی، شاید چهار پیکربندی موفق داشته باشیم. دلیل این رفتار شبکههای عصبی هنوز روشن نیست. محققان حوزه یادگیری عمیق معمولاً سعی میکنند کار خود را با شبکههایی آغاز کنند که بزرگتر از حد نیاز هستند، چرا که با این کار در واقع شانس موفقیت مدل را افزایش میدهند. پس از آموزش دادن چنین شبکه بزرگی، معمولاً فقط بخشی از اتصالات شبکه، قدرتمند بوده و بر خروجی اثر میگذارد و باقی اتصالات چنان سست هستند که نقش چندانی در خروجی شبکه نداشته و عملاً میتوان آنها را حذف یا با اصطلاح فنیتر «هرس» (prune) کرد بدون اینکه بر کارآیی شبکه اثر بگذارد. اگر بخواهیم آنچه گفته شد را خلاصه کنیم باید بگوییم برای اینکه به پیکربندی اولیه موفقی دست یابیم که قابل آموزش دادن باشد، مجبوریم کارمان را با شبکههایی بسیار بزرگتر از حد نیاز شروع کنیم. عملاً بخشهای قابلتوجهی از این شبکههای بزرگ پس از آموزش دیدن بیاستفاده میمانند که میتوان آنها را حذف کنیم. این، یعنی بخش بزرگی از زمان و توان خود را در طول فرایند آموزش به هدر دادهایم.
مطلب پیشنهادی

هرس پیش از آموزش
بر همین اساس، سالها است که محققان برای افزایش سرعت و بهبود عملکرد محاسباتی، شبکههایشان را پس از آموزش، هرس میکنند. اما تاکنون فرایند هرس پیش از آموزش دادن شبکه استفاده نشده است. این همان ایدهای است که محققان اِمآیتی روی عملی کردنش کار میکنند. جاناتان فرانکل (Jonathan Frankle) دانشجوی دکترای دانشگاه اِمآیتی معتقد است حالا که به اتصالات کمتری نیاز داریم چرا با شبکهای کوچک و بدون اتصالات اضافی شروع نکنیم و آنرا آموزش ندهیم؟ اساس پژوهش او و گروهش بر این حقیقت استوار است که مقادیر تصادفی اختصاص داده شده به اتصالات شبکه یا همان پیکربندی اولیه شبکه، بر پیکربندی نهایی که شبکه پس از آموزش دیدن به خود میگیرد تأثیر میگذارد.آنها از روش معمول هرس کردن شبکههای عصبی استفاه کردند تا اتصالات غیر ضروری یعنی آنهایی که وزن کمتری دارند از شبکه آموزش دیده حذف شوند. یافته کلیدی این پژوهش این است که بخشهای اضافی و هرسشده را میتوان برای همیشه کنار گذاشت و شبکه حاصل را برای کاربردی دیگر، دوباره آموزش داد. آنها شبکهای مشابه همان شبکه قبلی را این بار با حذف شاخههای اضافی و به صورت هرسشده آموزش دادند و با مقادیر اولیه شبکه نخست مقداردهی کردند.
با تکرار این فرایند هرس و آموزش، آنها سعی کردند این موضوع را بررسی کنند که به چه اندازه میتوان پیشرفت بدون توانایی آموختن شبکه را کاهش داد. آنها این کار را دهها هزار بار روی شمار زیادی از شبکههای مختلف در شرایط متنوع آزمودند و به شبکههای بسیار بهینهتر از نسخههای اولیه دست یافتند.
فرضیه بلیت بختآزمایی
بر اساس این یافته، فرانکل و همکارش مایکل کاربین (Michael Carbin) که استادیار اِمآیتی است فرضیه «بلیت بختآزمایی» را مطرح کردند.

شکل۲- مایکل کاربین، استادیار دانشگاه اِمآیتی (سمت چپ) در کنار جاناتان فرانکل دانشجوی دکترای این دانشگاه
وقتی شما پیش از آغاز آموزش، بهطور تصادفی قدرت اتصالات یک شبکه عصبی را مقداردهی میکنید درست مثل این است که کیسهای از بلیتهای بختآزمایی دارید و امید دارید که در کیسه، دستکم یک بلیت برنده باشد که بلیت برنده در اینجا همان پیکربندی اولیهای است که سادهتر میآموزد و یک مدل موفق را به وجود خواهد آورد. آغاز کردن با یک شبکه عصبی بزرگتر به منزله خریدن بلیتهای بیشتر است. شما برای حل مسأله از توان پردازشی بیشتری استفاده نکردهاید بلکه شانس دستیابی به یک پیکربندی مناسب را افزایش دادهاید. همینکه پیکربندی برنده را یافتید، قادر هستید از آن بارها و بارها و در مصارف دیگر استفاده کنید به جای اینکه مسابقه بخت آزمایی را از ابتدا شروع کنید و یک شبکه بزرگ جدید را آموزش دهید. به عقیده فرانکل نیازی نیست که با شبکهای بزرگ شروع کنیم. از دید این گروه، آموزش دادن شبکههای عصبی بزرگ به نوعی شبیه این است که شرکتکننده برای اطمینان از اینکه در بختآزمایی برنده خواهد شد، همه بلیتها را بخرد. کاری که این محققان میخواهند انجام دهند یافتن راهی است که از همان آغاز بتوانند بلیتهای برنده را انتخاب کنند.
گامهای بعدی
در این رابطه پرسشهای زیادی مطرح میشود. نخست اینکه چگونه بلیت برنده را پیدا میکنید؟ فرانکل و کاربین حالات مختلف آموزش و هرس یک شبکه بسیار بزرگ با یک مجموعه داده را برای استخراج بلیت برنده آزمودند و شبکه حاصل را برای مجموعه داده دیگر استفاده کردند. پرسش دومی که مطرح میشود این است که آموزش دادن یک پیکربندی برنده چه محدودیتهایی دارد؟ احتمالاً انواع مختلف دادهها و وظایف یادگیری عمیق، پیکربندیهای متفاوتی را هم طلب میکنند. پرسش سوم این است که کوچکترین شبکه ممکن با حداکثر کارآیی کدام است؟ فرانکل دریافت که از طریق یک فرآیند تکراری آموزش و هرس، میتوان اندازه شبکه را بین ۱۰ تا ۲۰ درصد اندازه اولیهاش کاهش داد. او معتقد است حتا میتوان اندازه شبکه را کوچکتر هم کرد.
در حال حاضر گروههای تحقیقاتی زیادی از جامعه هوش مصنوعی روی این موضوع در حال کار هستند. بهعنوان مثال، محققی از دانشگاه پرینستون در حال آزمودن نتایج تحقیقی است که به پرسش دوم میپردازد. گروهی از محققان شرکت اوبر نیز به مطالعه تمثیل بلیتهای بختآزمایی پرداختهاند. نکته بسیار جالب تحقیق اوبر این است که آنها دریافتند پیکربندی برنده بدون دریافت هرگونه آموزشی، عملکرد فوقالعاده بهتری نسبت به شبکه بزرگ آموزش ندیده اصلی دارد. به بیان دقیقتر، عمل هرس یک شبکه برای به دست آوردن یک پیکربندی برنده، خودش یک روش مهم آموزش شبکه است.
مطلب پیشنهادی

تولدی دوباره برای شبکههای عصبی
فرانکل پیشبینی میکند که در آینده بسیاری از افراد این امکان را خواهند داشت بدون نیاز به امکانات شرکتهای بزرگ، پیکربندیهای اولیه برنده را پیدا کنند و آنها را به همراه توضیحاتی در مورد کاربردشان در قالب یک پایگاه داده اپنسورس بهاشتراک گذارند. او معتقد است کاهش هزینه و بهبود سرعت آموزش سبب خواهد شد که تحقیقات هوش مصنوعی بهطور چشمگیری سرعت گرفته و از انحصار شرکتها خارج شود و به افراد اجازه خواهد داد بدون در اختیار داشتن سرورهای بزرگ، کار آموزش شبکه را روی لپتاپهای کوچک و حتا تلفنهای همراه انجام دهند. چنین امکانی تأثیر بسیار مهمی بر حوزه هوش مصنوعی خواهد گذاشت. اگر شما به جای استفاده از ابر، بتوانید شبکه عصبی خود را بهطور محلی و روی دستگاه آموزش دهید، خواهید توانست سرعت فرایند آموزش و امنیت دادهها را بهبود دهید. یک دستگاه پزشکی مبتنی بر یادگیری ماشین را تصور کنید که در طی روند استفاده، قادر است خودش را بهبود دهد بدون اینکه مجبور باشد دادههای بیماران را برای سرورهای گوگل و آمازون ارسال کند.
نتایج این تحقیق شاید یادگیری انتقالی (transfer learning) را نیز متحول کند و بهتوان از شبکهای که بهطور مثال برای شناسایی تصویر آموزش دیده در کاربردی کاملاً متفاوت استفاده کرد. در حال حاضر یادگیری انتقالی بدین صورت است که شبکهای برای کاربردی آموزش داده میشود و سپس با افزودن لایهای دیگر، آنرا برای وظیفهای دیگر آموزش میدهند. در بسیاری از موارد، شبکهای که برای یک هدف آموزش دیده است را میتوان برای اهداف دیگری نیز استفاده کرد.
نتایج یک هرس هوشمند
هنوز راهکار این محققان بهینه نیست، چراکه آنها مجبورند فرایند آموزش و هرس یک شبکه عصبی کامل را بارها انجام دهند تا زیرشبکه موفق را بیابند. مایکل کاربین بر اساس یافتههای گروهش معتقد است اگر بتوانیم بهطور دقیق مشخص کنیم کدام بخش از شبکه، همان زیرشبکه مورد نظر است، آنگاه خواهیم توانست کل فرایند پرهزینه آموزش را سادهتر و بهصرفهتر برگزار کنیم. یافتن چنین زیرشبکهای علاوه بر صرفهجویی در زمان، این امکان را فراهم خواهد کرد که افراد مختلف بدون نیاز به شرکتهای بزرگ فناوری بتوانند مدلهای عصبی قابل استفاده و مفیدی تولید کنند. دانیل روی (Daniel Roy) استادیار دانشگاه تورنتو در مورد تحقیق گروه اِمآیتی میگوید: « درک فرضیه بلیت بختآزمایی احتمالاً تا سالها محققان را درگیر خواهد کرد.» او معتقد است نتایج این پژوهش کاربردهایی در فشردهسازی و بهینهسازی شبکه خواهد داشت
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.






















نظر شما چیست؟