2016 را میتوان سالی پررونق در عرصه دادههای حجیم دانست، زیرا سازمانهای بیشتری به ذخیره، پردازش و استخراج همه نوع فرمت و اندازهای از داده پرداختند. در سال 2017 نیز سیستمهایی که از دادهها در مقیاس...
هرچه اهمیت تجزیه و تحلیل بزرگ دادهها در شرکتهای SaaS (نرمافزار بهعنوان خدمات) بیشتر میشود، رقابت برای دستیابی به سطوح جدید و بیسابقه در آنها نیز بیشتر میشود. با فرصتهای شغلی گوناگون فراهم...
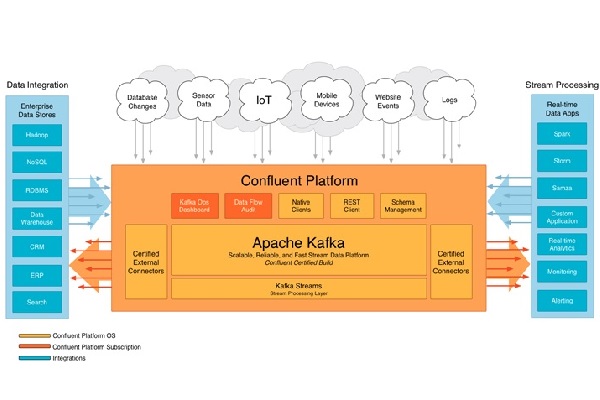
کافکا معماری پردازش جریان دادهها است که اولین بار در سال 2011 از سوی مهندسان لینکدین به منظور اداره کردن حجم انبوهی از دادههایی که به صورت بلادرنگ تولید میشوند ابداع گردید. کافکا اغلب در معماری...