

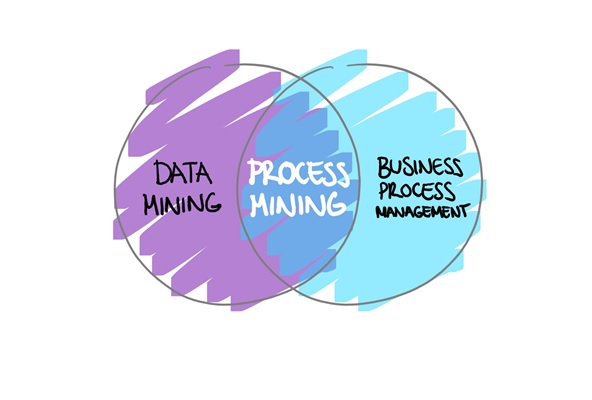
فرآیندکاوی چیست؟
فرایندکاوی (Process mining) بین هوش محاسباتی و دادهکاوی از یک سو و مدلسازی و تحلیل فرایندهای سازمان از دیگر سو قرار دارد. هدف فرآیندکاوی کشف، نظارت و بهبود فرایندهای واقعی از طریق استخراج دانش از دادههای ذخیره شده در سیستمهای اطلاعاتی است. فرآیندکاوی بیشتر به تحلیل فرایندها با استفاده از گزارش رخدادها میپردازد. تکنیکهای کلاسیک دادهکاوی نظیر خوشه بندی، طبقهبندی، انجمن یابی و ... روی مدلهای فرایند تمرکز ندارند و فقط برای تحلیل گام مشخصی در فرایند کلی استفاده میشوند. فرآیندکاوی دیدگاه فرآیندی را به داده کاوی می افزاید. تکنیکهای فرایندکاوی از دادههای رخدادهای ثبت شده برای کشف و تحلیل و بهبود فرآیند استفاده میکنند. هر رخداد ثبت شده به یک فعالیت اشاره دارد و مرتبط با یک نمونه فرآیند است.
فرایندکاوی به چه زیرشاخههایی تقسیم میشود؟
تکنیکهای فرایندکاوی، براساس دادههای رخداد، به سه دسته کلی تکنیکهای کشف فرایند (process discovery)، تکنیکهای بررسی انطباق (conformance checking) و تکنیکهای بهبود فرآیند (process enhancement) تقسیم میشود.
گروه اول یا همان تکنیکهای کشف فرایند دادههای رخداد را دریافت کرده و یک مدل بدون استفاده از هیچ اطلاعات پیشینی تولید مینمایند. گروه دوم تکنیکهای بررسی انطباق هستند و به بررسی این موضوع میپردازند که آیا فرایند واقعی که در حال اجرا در سازمان بوده منطبق با مدل کشف شده است و بلعکس. تکنیکهای دسته سوم هم به این موضوع میپردازند که آیا میشود با استفاده از دادههای رخداد یک فرایند را ارتقا یا توسعه داد. به عنوان مثال با استفاده از برچسب زمانی در دادههای ثبت شده میتوان مدل را طوری توسعه داد که گلوگاهها، زمان انتظار برای دریافت خدمت و زمان توان عملیاتی را نشان دهد. برخلاف روشهای تحلیلی دیگر، فرآیندکاوی فرایند محور است و نه داده محور اما با داده کاوی در ارتباط است.
فرایندکاوی چه تفاوتی با دادهکاوی دارد؟
فرآیندکاوی قدرت دادهکاوی و مدلسازی فرایند را ترکیب میکند با تولید خودکار مدل فرایندها بر مبنای لاگ های رخداد، فرآیندکاوی باعث ایجاد مدلهای زنده با قابلیت به روز رسانی بالا میشود.
حجم عظیمی از دادهها
فرآیندکاوی مشترکات زیادی با دادهکاوی دارد. بهطور مثال هر دو با چالش پردازش حجم بزرگ دادهها مواجه هستند. سیستمهای فناوری اطلاعات دادههای زیادی درباره فرایندهای تجاری مورد پشتیبانی خود جمعآوری میکنند. این دادهها به خوبی بیانگر آنچه در دنیای واقعی اتفاق افتاده هستند و قابلیت استفاده برای درک و بهبود سازمان را دارند. بر خلاف دادهکاوی، فرایندکاوی بر دیدگاه فرایندی تمرکز میکند؛ یعنی به یک اجرای فرایند از منظر تعدادی فعالیت اجرا شده نگاه میکند. بیشتر تکنیکهای دادهکاوی الگوها را در قالبی مانند قوانین یا درخت تصمیم استخراج میکنند. اما فرایندکاوی مدل فرایندهای کاملی ایجاد میکند و سپس از آنها برای شناسایی گلوگاه استفاده میکند. در دادهکاوی عمومیسازی به منظور جلوگیری از سرریز شدن دادهها امری بسیار مهم است. این یعنی میخواهیم تمام دادههایی را که با قانون کلی سازگاری ندارند دور بیندازیم. در فرایندکاوی نیز عمومیسازی در کار کردن با فرایندهای پیچیده و درک جریان فرایندهای اصلی لازم است. همچنین در بیشتر موارد درک استثناءها به منظور کشف نقاط ناکارآمدی و نیازمند بهبود ضروری به نظر میرسد. در دادهکاوی معمولاً مدلها برای پیشبینی نمونههای مشابه در آینده استفاده میشوند. در واقع روشهای دادهکاوی و یادگیری ماشین کمی وجود دارند که مانند یک جعبه سیاه پیشبینیهایی تولید میکنند بدون اینکه امکان برگشت به عقب یا بیان علت آنها را داشته باشند. از آنجا که فرایندهای تجاری کنونی خیلی پیچیده هستند پیشبینیهای دقیق معمولاً غیر واقعی هستند. دانش بدست آمده و بینش عمیقتر نسبت به الگوهای و فرایندهای کشف شده به رفع پیچیدگی کمک خواهد کرد؛ بنابراین اگرچه دادهکاوی و فرایندکاوی مشترکات زیادی دارند اما تفاوتهای پایهای بین آنها در کاری که انجام میدهند و جایی که مورد استفاده قرار میگیرند وجود دارد.
فرآیندکاوی با چه چالشهایی روبرو است؟
بهطور سنتی، کاوش فرایند در یک سازمان اجرا میگردد. اما با گسترش تکنولوژی وب سرویس، یکپارچگی زنجیره تأمین و محاسبات ابری، سناریوهایی پیش میآید که در آن دادههای چند سازمان برای آنالیز در دسترس میباشد. در حقیقت دو مشخصه برای کاوش فرایندهای بین سازمانی موجود میباشد. در سناریوی همکارانه، سازمانهای مختلف همگی باهم در جهت رسیدن به اهداف مشخصی همکاری داشته و نمونه فرایندها بین این سازمانها در جریان میباشد. در این مدل سازمانها همانند قطعات یک پازل میباشند. فرایند کلی به قطعاتی شکسته شده و بین سازمانها توزیع میشود تا هر سازمان وظیفه مربوط به خود را انجام دهد. آنالیز رویدادهای ثبت شده در تنها یکی از این سازمانها کافی نمیباشد. به منظور کشف فرایندهای انتها به انتها، رویدادهای ثبت شده سازمانهای مختلف باید بایکدیگر ادغام گردد که کار سادهای نمیباشد. سناریوی دوم این است که سازمانهای مختلف در عین حال که از زیرساختهای مشترکی استفاده مینمایند، فرایند یکسانی را اجرا نمایند. به عنوان مثال Saleforce.com را میتوانید در نظر بگیرید. این شرکت فرایند فروش شرکتهای دیگر را بر عهده دارد و مدیریت میکند. از یک طرف شرکتها از زیر ساخت این سایت استفاده میکنند و از طرف دیگر مجبور نیستند که دقیقاً یک فرایند قطعی را دنبال کنند (چراکه سیستم امکان تنظیمات اختصاصی در دنبال کردن فرایند به آنها میدهد. واضح است که آنالیز این تغییرات بین سازمانهای مختلف کار جذاب و جالبی میباشد. این سازمانها میتوانند از همدیگر یاد بگیرند و فراهم کنندگان سرویس ممکن است که سرویس هایشان را ارتقا بخشند و سرویسهای ارزش افزودهای را برمبنای نتیجه کاوشهای بین سازمانی ارائه نمایند. کاوش فرایند مهمترین ابزار برای سازمانهای مدرنی است که نیاز به مدیریت مناسب فرایندهای عملیاتی دارند. از یک سو با رشد باورنکردنی حجم داده روبرو هستیم و از دیگر سو فرایندها و اطلاعات باید بهطور مناسب جمعآوری شوند تا نیازمندیهای مربوط به کارایی، انطباق و خدمت رسانی پاسخ داده شود. علیرغم کاربردی بودن فرآیندکاوی، هنوز چالشهای عمدهای پیش رو میباشد که باید مورد توجه قرار گیرد. چالش اول یافتن، جمعآوری، یکپارچهسازی و پاکسازی دادههای رخداد است. در سیستمهای فعلی نیز انرژی زیادی باید صرف استخراج دادههای رویداد مناسب برای کاوش فرایند صورت گیرد. بهطور معمول، در این زمنیه چند مشکل وجود دارد که باید مرتفع گردد. بهطور مثال، ممکن است دادهها روی چندین منبع توزیع شده باشد. این اطلاعات باید ادغام گردند. این مشکل زمانی حادتر میشود که از چندین شناسه برای منابع مختلف استفاده شود. مثلاً یک سیستم از نام و تاریخ تولد برای شناسایی افراد استفاده کند و سیستم دیگر از شماره امنیتی اجتماعی فرد. دادههای سازمانی غالباً شیمحور و نه فرایند محور هستند. به عنوان مثال محصولات و کانتینرها میتواند تگهای RFID ایی داشته باشند که خودکار منجر به ثبت رکورد گردند. برای رصد کردن سفارش یک مشتری، این اطلاعات شی محور باید ادغام و پیش پردازش شوند. دادههای رویداد ممکن است ناکامل باشند. یکی از رایجترین مشکلات این است که رویدادها به صورت صریح به نمونههای فرایند اشاره نمیکنند. دادههای رویداد ممکن است حاوی اطلاعات پرت باشد. منظور از دادههای پرت نمونههایی است که از الگوی عمومی پیروی نکرده و به ندرت اتفاق میافتند. گزارش ممکن است حاوی اطلاعاتی با سطوح مختلف دانهدانه شدن باشد. دادههای لاگ بیمارستانی ممکن است به یک تست خون ساده اشاره کند یا اینکه به یک رویه پیچیده جراحی اشاره نماید. برای حل این مشکل نیاز به ابزارهای بهتر و متدولوژیهای مناسب تر میباشد. علاوه بر آن، همانطور که پیش تر نیز به آن اشاره شد، سازمانها باید با دادههای لاگ همانند شهروندان درجه یک برخورد کنند و نه به عنوان یک محصول جانبی. دومین چالش بزرگ در این زمینه استفاده از دادههای رویداد پیچیدهای است که ویژگیهای گوناگونی دارند. دادههای لاگ ممکن است که ویژگیهای خیلی متنوعی داشته باشند. بعضی از دادههای لاگ ممکن است که آنچنان بزرگ باشند که رسیدگی به آنها دشوار باشد و بعضی از آنها ممکن است آنقدر کوچک باشند که نتوان نتایج قابل اطمینانی از آنها استحصال کرد. ابزارهای موجود در مواجه با دادههای با ابعاد پتابایت دشواریهایی دارند. در کنار تعداد رکوردهای رویدادهای ذخیره شده ویژگیهای دیگری نظیر متوسط تعداد رویدادها در هر حالت، شباهت میان حالتها، تعداد رویدادهای منحصر به فرد و تعداد مسیرهای واحد نیز هستند که باید مورد توجه قرار گیرند. به عنوان مثال فایل لاگ داده L1 با مشخصات ذیل را در نظر بگیرید: ۱۰۰۰ حالت، بهطور متوسط ۱۰ رویداد به ازای هر حالت. فرض کنید فایل لاگ L2 حاوی تنها ۱۰۰ حالت باشد اما هر حالت حاوی ۱۰۰ رویداد باشد و همه رویدادها از یک مسیر واحد تبعیت کنند. پر واضح است که آنالیز L2 بمراتب دشوارتر از آنالیز L1 میباشد، علیرغم اینکه هر دو فایل سایز برابر و یکسانی دارند. از آنجایی که دادههای لاگ تنها حاوی نمونههای مثال میباشند، بنابراین نباید اینطور فرض شود که آنها کامل هستند. تکنیکهای کاوش متن باید با استفاده از «فرض جهان باز» با این عدم کامل بودن کنار بیایند: این واقعیت که اگر پدیدهای اتفاق نمیافتد به معنای عدم امکان رخداد آن نیست. این موضوع تعامل با دادههای لاگ با سایز کم و حاوی تغییرات زیاد را دشوار میکند. همانطور که پیشتر هم اشاره شد، بعضی از فایلهای لاگ ممکن است حاوی رکوردهایی با سطح انتزاع بسیار پایین باشند. دادههای با سطح پایین چندان مطلوب ذی نفعان نمیباشند؛ بنابراین عموماً سعی میشود تا دادههای سطح پایین با همدیگر تجمیع شوند تا دادههای با سطح بالاتر تولید گردد. به عنوان مثال، زمانی که فرایند تشخیص و درمان گروهی از بیماران آنالیز میشود، احتمالاً دیگر علاقهمند به دانستن نتایج آزمایشها انفرادی افراد نیستیم. در این گونه از موارد، سازمانها لازم است که از روش سعی و خطا استفاده نمایند تا دریابند که آیا دادهها مناسب برای کاوش فرایند میباشند؛ بنابراین ابزارها باید سرویس آزمایش امکانسنجی سریع برای یک پایگاه داده مشخص را فراهم نمایند. سومین چالش بزرگ در این زمینه رانش مفهومی (Concept Drift) است. عبارت رانش مفهومی در حوزه کاوش فرایند به موقعیتی اشاره میکند که در آن فرایند در عین حال که در حال آنالیز شدن میباشد، تغییر نیز میکند. به عنوان مثال در ابتدای یک فایل لاگ، ممکن است که دو فعالیت همزمان باشند در حالیکه در ادامه در لاگ این دو فعالیت ترتیبی شوند. فرایندها به دلایل مختلفی ممکن است تغییر کنند. غالباً دادههای ثبت شده کامل نیستند. مدلهای فرایندی معمولاً محدودیتی برای تعداد نامحدود نمونه فرایند (درحالت وجود حلقهها) ندارند. از طرفی، بعضی از نمونهها هم نسبت به سایرین رخداد بمراتب کمتری دارند؛ بنابراین اینکه فکر کنیم هر نمونه فرایند قابل رخدادی در فایل وقایع ثبت شده موجود میباشد، تصور نادرستی میباشد. برای اینکه نشان داده شود که تصور داشتن دادههای کامل، در عمل امکانپذیر نمیباشد، فرایندی را در نظر بگیرید که شامل ۱۰ فعالیت بوده و این فعالیتها بتوانند به صورت موازی اجرا شوند. همچنین فرض کنید که فایل رویدادهای ثبت شده حاوی ۱۰٬۰۰۰ نمونه فرایند باشد. تعداد حالتهای کلی (جایگشتها) در یک مدل با ۱۰ فعالیت همزمان، ۳٬۶۲۸٬۰۰۰=!۱۰ میباشد؛ بنابراین امکانپذیر نمیباشد که تمامی این نمونهها در فایل رویدادهای ثبت شده (تنها حاوی ۱۰٬۰۰۰) وجود داشته باشد. وجود دادههای نویز (دادههای با رخداد کم) بر پیچیدگیها میافزاید. ساخت مدل برای رفتارهایی که به ندرت رخ میدهند (دادههای نویز) کار بسیار دشواری میباشد. در این گونه موارد، برای پردازش این دسته از رفتارها بهتر است که از چک کردن مطابعت استفاده شود. نویز و ناکامل بودن، کشف فرایند را به یکی از پرچالشترین مسائل تبدیل کردهاست. تعادل برقرار کردن بین معیارهای سادگی، سازگاری، دقت و عمومیت داشتن کار پرچالشی میباشد. به همین دلیل اکثر تکنیکهای قدرتمند کاوش فرایند پارامترهای متنوعی را فراهم میسازند. الگوریتمهای جدیدی برای تعادل برقرار کردن بین این معیارها نیاز است.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.






















نظر شما چیست؟