


بسیاری از ایدههای مدرن پیرامون ارائه یک تجربه خرید آنلاین رضایتبخش مانند پیشنهاد «خرید چند محصول مکمل» و «محصولات مشابه» به واسطهها یکسری محدودیتها در زمان طراحی بانکهای اطلاعاتی اولیه قابل اجرا نبودند و به همین ترتیب برخی فرآیندهای کاری به اندازهای پیچیده و پر هزینه بود که شرکتها از انجام آنها منصرف میشدند.
بهطور مثال، یک فروشگاه نگهداری از حیوانات خانگی را در نظر بگیرید. مسئولان این فروشگاه میتوانند کار را با ساخت یک وبسایت معمولی که توسط یک پایگاه داده رابطهای پشتیبانی میشود آغاز کنند، سفارشات را دریافت و تلاش کنند در سریعترین زمان ممکن محصول سفارش داده شده را به دست مشتری برسانند. هر از گاهی نیز ممکن است به امید افزایش سطح تعاملات و سفارشگیری بیشتر از طریق ایمیل و پیامک با ارسال پیشنهادات فروش ویژه با مشتريان در تعامل باشند. با اینحال، به نظر نمیرسد چنین رویکردی به دلیل ارائه نکردن پیشنهادات شخصی به ویژه در یک بازار پر ازدحام به نتیجه برسد.
پایگاه داده نموداری (Graph Database)
پایگاه داده نموداری یا پایگاه دادههای مبتنی بر نظریه گراف یک راهکار نوآورانه و قدرتمند برای حل مسائل مربوط به دادههای متصل به هم به شیوهای نزدیک به تصورات انسانها است. این فناوری با وجودی که نسبتا جدید است، اما با استقبال خوبی روبرو شده است. در آخرین نظرسنجی انجام شده توسط DATAVERSITY مشخص شد تقریبا بیست و پنج درصد شرکتها قصد دارند طی دو سال آینده از پایگاههای داده گراف استفاده کنند. چرا؟ در این مقاله به نحوه کار پایگاههای داده گراف، وجه تمايز آن و مزایایی که میتواند برای اپلیکیشن شما داشته باشد نگاه دقیقتری خواهیم داشت.
پایگاه داده نموداری چیست؟
یک پایگاه داده نموداری روشی انعطافپذیرتر و قابل رویت برای ذخیرهسازی دادهها است. در حالی که اغلب موتورهای پایگاه داده تنها از دادههایی پشتیبانی میکنند که میتوانند به عنوان مجموعهای از جداول مرتبط به هم که از لحاظ منطقی به یکدیگر وصل هستند (برای مثال، از طریق قیدها و کلید خارجی) ارائه شود، پایگاههای داده نموداری از یک رویکرد مبتنی بر دو مفهوم ساده و قدرتمند گرهها و روابط تبعیت میکند. گرهها (Node) نشاندهنده موجودیتها یا اشیای (اغلب اسامی) موجود در دامنه هستند، در حالی که روابط (relationships) نشان میدهند گرهها چگونه رفتار میکنند و با یکدیگر مرتبط (اغلب افعال) هستند. فرض کنید فروشگاه نگهداری از حیوانات خانگی مثال ما میخواهد شناخت دقیقتری از مشتريان بهدست آورد و به همین دلیل شروع به ثبت نوع و تعداد حیوانات خانگی مشتریان میکند. آنها کار را با طراحی یک نمودار آغاز میکنند (شکل 1).
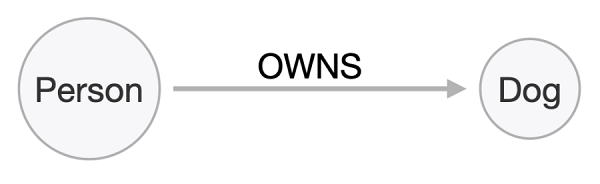
برای شروع تنها به دو گره شخص (Person) و سگ (Dog) و یک ارتباط مالکیت بین این دو (OWNS) احتیاج است. روابط در یک پایگاه داده نموداری جهتدار (directed) هستند و توسط فلش مشخص میشوند (شخص تنها مالک سگ است). بعد از این که اصل اولیه برقرار شد، میتوانیم محتوای دیگر را به نمودار اضافه کنیم (شکل 2):
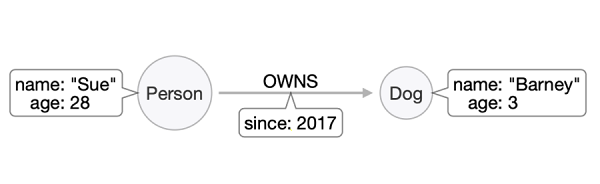
حالا گرههای شخص و سگ هر کدام دارای مشخصههای نام (name) و سن (age) هستند. در نموارد فوق رابطه میان گرههای شخص و سگ نشان میدهد فردی بهنام Sue چه مدت است که مالک سگی بهنام Barney است. توجه کنید که چگونه به روشی یکسان مشخصهها را به گرهها و روابط ضمیمه کردیم. چنین کاری امکانپذیر است، زیرا پایگاههای داده نموداری بر خلاف پایگاههای داده رابطهای با روابط به عنوان شهروندان درجه یک (first class citizens) رفتار میکنند به این معنا که نقش آنها در پایگاه داده به همان میزان اهمیت گرههایی است که به آن متصل شدهاند. نکته مهم در مورد نمودارها، حتا مثال سادهای که به آن اشاره کردیم، این است که فرآیند فوق نه تنها راهکاری برای ذخیرهسازی دادهها نشان میدهد، بلکه میتوانید برای طراحی اولیه مدل دادههای خود از این راهکار استفاده کنید. نمودارها ذاتا قابل فهم و چشمنواز هستند، به همین دلیل زمانهایی که نیاز است کار را ساده شروع کنید و به مرور زمان محتوای بیشتری به آن اضافه کنید یک انتخاب منحصر بهفرد هستند.

شکل 3
همچنین افراد با تجربه فنی کم منطق این مدل پایگاههای داده را درک میکنند. حالا فرض کنیم Sue تصمیم میگیرد یک گربه خریداری کند. برای این کار تنها لازم است گره دیگری به پایگاه داده اضافه شود و از طریق یک رابطه OWNS جدید به Sue متصل شود. حالا این فرد مالک یک سگ و یک گربه است که میتوان با روش یکسان به هر دو موجودیت دسترسی داشت (شکل 3) ممکن است بخواهیم در مورد حیوانات خانگی Sue اطلاعات بیشتری بهدست آوریم یا ببینیم هر مشتری بهطور متوسط چند حیوان خانگی دارد. گرهها میتوانند هر تعداد برچسبی که لازم است داشته باشند، بنابراین علاوه بر اینکه برای جداسازی آنها از یکدیگر برچسب Dog و Cat را به آنها اختصاص دادیم، میتوانیم برای قرار دادن آنها در یک گروه برچسب Pet را به آنها اضافه کنیم (شکل 4):

شکل 4
مقايسه پایگاههای داده نموداری با پایگاههای داده رابطهای
فرآيند اضافه کردن تدریجی اطلاعات بیشتر در حالی که منطق کار حفظ شده نشان میدهد تکامل یک پایگاه داده نموداری کاملا ساده و مطابق با خواستهها است. اکنون تصور کنید قرار است همین سناریو را بر مبنای یک پایگاه داده رابطهای پیادهسازی کنیم و از طریق بهکارگیری چند جدول و روابط میان آنها به اطلاعات دقیقی در مورد مشتریان و نیازهای آنها دست پیدا کنیم (شکل 5).

در مدل رابطهای حداقل به سه جدول نیاز است که هر کدام با یک کلید خارجی (foreign key) به یکدیگر مرتبط شدهاند. برای بازیابی هر یک از اطلاعات مورد نیاز باید به یکباره دادهها را از تمام آنها بارگیری کرد و هر بار منطق الحاق (اتصال) را مشخص کرد. همین رویه در نمودار مثال ما تنها از طریق سه گره و دو رابطه قابل انجام است. اگر چه در این مثال ممکن است تفاوت چندان فاحش نباشد، اما با افزایش اندازه، پیچیدگی مدل داده آشکار میشود. تفاوتهای روشنی میان یک پایگاه داده نموداری و یک پایگاه داده رابطهای وجود دارد که برخی از آنها به شرح زیر هستند:
1. کوئریگیری توصیفپذیر: پیادهسازی بر اساس نوع پلتفرمها متفاوت است، اما اغلب پایگاههای داده نموداری به زبان کوئریگیری دستوری کاملا توصیفی مجهز هستند که امکان مشخص کردن محتوایی که به دنبال آن هستید را فراهم میکنند. زبان کوئریگیری Cypher مورد استفاده در Neo4j میتواند دادههای مربوط به Sue و حیوانات او در مثال بالا را به سادگی استخراج کند:
MATCH (s:Person {name:"Sue"})-[r:OWNS]->(p:Pet)
این کوئری ساده و قابل درک تمام مشخصههای Person (s)، هر Pet (p) و تمام ارتباطات بین آنها (r) را نشان میدهد. اگر در آینده مشخصههای بیشتری به هر کدام از این موجودیتها اضافه کنیم، آنها نیز بهطور خودکار دریافت میشوند. اکنون این محاوره را با یک محاوره رابطهای مقايسه کنید. محاوره بالا در ارتباط با یک بانکاطلاعاتی رابطهای به شرح زیر نوشته میشود:
SELECT People.*, Pets.* FROM People JOIN PeoplePets ON People.id = PeoplePets.id JOIN Pets ON PeoplePets.pet_id = Pets.pet_id WHERE People.id = 123;
هر بار که بخواهید به مشخصههای یک داده دسترسی پیدا کنید باید ماهیت رابطهای بین آنها را بهطور کامل مشخص کنید. اگر به هر دلیلی اسامی یا نوع دادههای این ستون ها تغییر پیدا کند باید دستورات بهروزرسانی شوند. چنین مشکلی در پایگاههای داده نموداری وجود ندارد، زیرا ارتباطات به سادگی از طریق دو گره به یکدیگر متصل شدهاند و دیگر به دستوارت join نیازی نیست.
2. انعطافپذیری بیشتر در تطبیق با مدل کاربردی: هیچ مدل دادهای در دنیای واقعی برای مدت طولانی ثابت نمیماند. کسبوکارها ممکن است اهداف خود را تغییر دهند یا بخواهند بدون نیاز به بازسازی پایگاه داده بزرگ خود ایدههای جديد را آزمایش کنند. با پایگاههای داده نموداری، اضافه کردن برچسب به گرهها، مشخصه به رابطهها یا باز چینش بخشهای بزرگی از نمودار کار راحتی است. وقتی دادهای از بین میرود دیگر مثل پایگاه داده رابطهای کلید خارجی یا جدولی وجود ندارد که نیاز به رسیدگی و پاکسازی داشته باشد. در این حالت سرپرستان بانکاطلاعاتی بیشتر وقت خود را روی دادهها صرف میکنند و کمتر روی زیرساخت داده متمرکز میشوند.
3. عملکرد عالی هنگام پیمایش روابط داده: ماهیت پایگاههای داده نموداری بهگونهای بهینهسازی شده تا دادهها مطابق با نیازهای کاری ذخیرهسازی شوند. این حرف به معنای آن است که Sue و دو حیوان خانگی او اگر چه گرههای کاملا جدا از هم هستند و اطلاعات مربوط به Sue ممکن است با فاصله زمانی طولانیمدت به پایگاه داده اضافه شده باشد، اما درون فایلهایی نوشته میشوند که تا حد امکان به هم نزدیک هستند. رویکرد فوق باعث میشود بازیابی دادههای مرتبط سریعتر از یک پایگاه داده رابطهای انجام شود.
چه نوع دادههایی در یک پایگاه داده نموداری بهتر کار میکند؟
بهترین عملکرد پایگاههای داده نموداری مربوط به زمانی است که قرار است دادههای حاوی روابط با زمینه مرتبط و مهم با یکدیگر مدیریت شوند. یک مثال عالی در این زمینه فروشگاه آنلاینی است که میخواهد مشتريان خود را شناسایی کند و با آنها تعامل داشته باشد. نمودارها میتوانند کارهایی فراتر از نشان دادن یک تعامل ساده را نشان دهند. از مهمترین کاربردهای یک پایگاه داده نموداری به موارد زیر میتوان اشاره کرد:
نمودارهای دانش – سازمانهایی مثل ناسا از پایگاه داده نموداری برای ثبت اتصالات منطقی بین آزمايشها و پروژهها استفاده میکنند. به این معنا که تلاشهای آینده آنها میتواند از تجارب کارهای گذشته برای افزایش راندمان و جلوگیری از تکرار اشتباهات گذشته بهره بگیرد.
- موتورهای پیشنهاددهنده– موتورهای پیشنهاد دهنده بخش جداییناپذیر تجارت آنلاین هستند. موتورهایی که محصولات و خدماتی که به کاربران توصیه میکنند ماحصل ارزیابی الگوی رفتارهای کاربران با افرادی است که خریدهای مشابه انجام دادهاند.
- مدیریت زنجيره تامین – فرآیندهای تولید مدرن اغلب به مولفههای مختلف از مکانهای مختلف وابسته هستند، بنابراین درک وابستگیها در یک فرآیند توزیعی مهم است. یک پایگاه داده نموداری به شناسایی این وابستگیها کمک میکند.
- روشی ساده برای آزمایش پایگاههای داده نموداری
بهترین راه یادگیری یک فناوری جدید آزمایش آن است. برای پایگاههای داده نموداری، Neo4j یک پایگاه داده نموداری عالی برای آزمایش است که مستندات کاملی را برای آموزش ارائه میکند. برای آزمایش سریع Neo4j، از راهکارهای میزبانی شده توسط خدماتدهندگان استفاده کنید تا به راهاندازی و پیکربندی سرور اختصاصی نیاز نباشد. بهطور مثال، آمازون یک نسخه توسعه Neo4j به نشانی (https://neo4j.com/developer/neo4j-cloud-aws-ec2-ami/) را ارائه کرده است. Heroku به نشانی (https://www.heroku.com) نمونه رایگان دیگری است که یک راهکار PaaS توسعه را ارائه کرد است.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.






















نظر شما چیست؟