










تردیدی نیست که وابستگی جامعه بشری به شبکههای کامپیوتری ـ و به طور خاص اینترنت ـ روز به روز افزایش مییابد. با این حساب وظیفه سنگینی بر عهده مهندسان شبکه است که به این نیاز و وابستگی پاسخ شایستهای بدهند. در این راستا، راهکارهای گوناگونی از ابتدای پیدایش اینترنت برای بهبود عملکرد آن پیشنهاد شده است؛ از روشهایی که بر روی معماری فعلی بنا میشوند تا راهکارهایی که اساس شبکه را دگرگون میسازند. با این حال، سؤال اساسی این است که چه راههای نرفتهای در این مسیر میتوان یافت؟ البته که این سؤال هیچگاه به پایان نمیرسد، زیرا خلاقیت و نوآوری انسان را انتهایی نیست. با این حال، این نوشتار یکی از پاسخهایی را که به نظر میرسد اخیراً مورد توجه بیشتری قرار گرفته است، بررسی میکند. یادگیری ماشین یکی از راههایی است که انتظار میرود شبکههای بهتری برای ما بیافریند و ما قصد داریم به آن بپردازیم.

یادگیری ماشین در یک نگاه
به موازات پیشرفتها در حوزه شبکه، یادگیری ماشین نیز در حال رشد و گسترش بوده است. یادگیری ماشین به زبان ساده یعنی یک سیستم پردازشی که میتواند بر اساس یک سری داده ورودی در آینده تصمیمات بهتری بگیرد. به بیان دیگر، سیستم یادگیری یک مجموعه الگو در دادههای ورودی پیدا میکند که این الگوها برای تصمیمگیری در هنگام مواجهه با دادههای جدید مفید هستند. مثال بارز یادگیری ماشین، سیستم شناسایی گفتار است که در ابتدا تعدادی نمونه صوتی به همراه معادل متنی آن به سیستم داده میشود. پس از آن اگر سیستم بهدرستی آموزش ببیند، میتواند نمونههای صوتی جدید را با دقت قابل قبولی به متن تبدیل کند. البته شرطی که در جمله قبلی ذکر شد، شرط سادهای نیست. زیرا برآورده ساختن شرایط آموزش درست نیاز به دانش و مهارت فراوانی دارد. مثلاً فراهمسازی داده آموزشی بهمقدار کافی و انتخاب مدل درست از بین مدلهای متنوع، از چالشهای این مسیر به شمار میآید. بسیاری از این چالشها حل شدهاند و در حال حاضر افزون بر شناسایی متن، کاربردهای بسیار متنوعی برای یادگیری ماشین پدیدار شده است که میتوان به پردازش تصویر، تشخیص بیماری و سیستمهای توصیهگر اشاره کرد.
اما چرا از یادگیری ماشین برای بهبود رفتار شبکه استفاده نکنیم؟ احتمالاً این رویکرد در گذشته نیز مطرح شده باشد، اما یادگیری ماشین چنین توانایی را در آن زمان نداشته است. در بند قبلی به لزوم فراهمسازی داده آموزشی کافی برای یادگیری سیستم اشاره کردیم. این چالش با افزایش حجم دادههای عبوری در اینترنت نسبتاً برطرف شده است. همچنین، مدلهای مناسبی برای مدیریت پیچیدگی این مسئله مورد نیاز است که با ظهور یادگیری عمیق به نظر میرسد این چالش نیز حل شده باشد. در بخش بعدی یادگیری عمیق را مورد بررسی قرار میدهیم.

یادگیری ماشین از نوع عمیق
یادگیری عمیق یا ژرف یک نوع خاص از یادگیری ماشین با ناظر است که در آن ورودی وارد یک گراف به فرم شکل 1 میشود. این گراف در واقع همان شبکه عصبی است که تعداد لایههای بیشتری دارد. ورودی شبکه عصبی مجموعهای از اعداد است که با عبور از فِلِشها به لایه بعدی میرسند (شکل 2). هر فلش یک ضریب دارد که عدد ورودی در آن ضرب میشود. اعدادی که به یک گره میانی میرسند، با یکدیگر جمع میشوند و سپس یک تابع روی مجموع اعمال میشود. برای مثال در شکل 2، اعداد ورودی (صفر، یک و یک) به ترتیب در 2.2-، 3.1- و 4.6- ضرب میشوند و مجموع اعداد حاصل برابر با 7.7- میشود. مقادیر سایر گرههای شبکه عصبی به همین شیوه محاسبه شده و درنهایت خروجی ساخته میشود که تابعی است از ورودی شبکه و ضرایب فلشها. لازم به ذکر است هر چند گره که موازی با یکدیگر باشند، تشکیل یک لایه را میدهند. با این حساب، شبکه شکل 1 پنج لایه دارد که به لایههای میانی لایه پنهان میگویند. (شکل 1 و شکل 2)
 شکل 1
شکل 1
اگر یک شبکه یادگیری عمیق بهدرستی آموزش ببیند یا به بیان دقیقتر به سیستم یک داده آموزشی مناسب داده شود، به نحوی که بتواند ضرایب را بهدرستی تنظیم کند، با هر ورودی جدید میتوان به خروجی مناسب دست یافت. اینکه فرآیند یادگیری چگونه باشد یا خروجی را چگونه میتوان تفسیر کرد، خارج از حوزه بحث ما است. اگر با این مفاهیم آشنایی کافی ندارید، میتوانید به مطالب موجود در وبسایت ماهنامه شبکه یا مراجع دیگر مراجعه کنید. البته برای خواندن ادامه این متن فقط کافی است بدانید یادگیری عمیق یک سیستم محاسباتی است که ورودی را گرفته و یک خروجی معنادار میدهد. برای مثال در شکل 3، سیستم یادگیرنده ماتریس معادل تصویر عددهای دستنویس را گرفته و رقم متناظر با هر عکس را بهعنوان خروجی برمیگرداند.
 شکل 2
شکل 2
لایههای پنهان در این شبکه نقش استخراج ویژگی از عکس را به عهده دارند و مشابه یک سیستم پردازش تصویر عمل میکنند که بدون نیاز به دانش کارشناس پردازش تصویر طراحی شده باشد. (شکل 3)
ممکن است این پرسش به ذهن شما برسد که یادگیری عمیق چه مزیتی بر سایر شیوههای یادگیری دارد و نقطه ضعف آن چیست؟ در واقع یک شبکه یادگیری عمیق تعداد فراوانی پارامتر دارد و گاهی به میلیونها پارامتر میرسد (شبکه شکل 1 بهعنوان یک نمونه ساده نزدیک به 300 فلش دارد که هرکدام یک پارامتر قابل تنظیم است). چنین سیستم یادگیری با فرض وجود داشتن تعداد داده زیاد برای آموزش آن، قدرت الگویابی و تشخیص بالایی خواهد داشت. اما اگر داده کافی موجود نباشد، این ویژگی مثبت به یک نقطه ضعف تبدیل میشود. در این حالت پارامترهای سیستم کاملاً مطابق با داده آموزشی تنظیم میشوند و سیستم قدرت تشخیص خود را برای دادههای جدید از دست میدهد. تفاوتهای دیگری نیز بین یادگیری عمیق و سایر شیوههای مرسوم قابل ذکر است، از جمله میزان نیاز به دانش انسان در ساختن مدل که در یادگیری عمیق ناچیز است (برخلاف بسیاری از مدلهای مرسوم که نیازمند دانش اولیه هستند) و تفاوتهای دیگر که شرح آنها در این مختصر نمیگنجد.
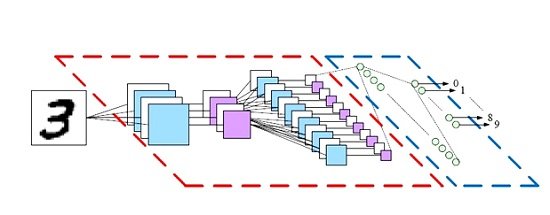 شکل 3
شکل 3
پیوند شبکه و یادگیری ماشین
حال میخواهیم به برخی از کاربردهای متصور برای یادگیری ماشین در شبکه با تمرکز بر یادگیری عمیق بپردازیم. روشهای کلاسیک یادگیری ماشین شامل روشهای یادگیری با ناظر از جمله درخت تصمیمگیری و روشهای آماری بِیزین و روشهای بدون ناظر است. یادگیری عمیق چنانچه در بخش قبلی ذکر شد، یکی از انواع یادگیری با ناظر است که اخیراً مورد توجه قرار گرفته است.
- شبکههای حسگر بیسیم: روشهای مختلف یادگیری ماشین از جمله روش بِیزین در شبکههای حسگر بیسیم پیشنهاد شده است. اما این روشها نیاز به یک دانش آماری اولیه دارند که استفاده گسترده از آنها را محدود میسازد. اما یادگیری تقویتی عمیق که ترکیبی از یادگیری عمیق و یادگیری تقویتی است، در این زمینه میتواند مفید باشد. برای مثال، خوشهبندی در این شبکهها اهمیت بالایی دارد که بهوسیله آن میتوان اطلاعات حسگرها را از طریق سرگروه در هر خوشه دریافت کرد (که به کاهش مصرف انرژی حسگرها منجر میشود). اینکه هر حسگر در کدام خوشه قرار بگیرد، یک مسئله دشوار است که با یادگیری تقویتی عمیق به شیوه بهتری قابل انجام است.
- کلاسبندی ترافیک شبکه: با دستهبندی ترافیک عبوری در شبکه به کلاسهای مختلف، اهداف مختلفی از جمله تأمین امنیت، ارائه کیفیت سرویس به کاربران و پیکربندی شبکه برآورده میشود. برای نمونه در بحث امنیت شبکه، به طور معمول ترافیک را بر اساس مشخصات آن به دو دسته مخرب و ترافیک عادی تقسیمبندی میکنند. مشخصات ترافیک میتواند اطلاعات داخل بستهها (سرآیند یا متن بستهها) یا پارامترهای آماری آن (نظیر توزیع آماری طول بستهها) باشد. قاعدتاً مشخصات ترافیک کلاسهای مختلف با یکدیگر از برخی جنبهها تفاوت دارد که سیستم یادگیری این تفاوتها را فرا میگیرد.
چنین سیستم یادگیری با فرض وجود داشتن تعداد داده زیاد برای آموزش آن، قدرت الگویابی و تشخیص بالایی خواهد داشت. اما اگر داده کافی موجود نباشد، این ویژگی مثبت به یک نقطه ضعف تبدیل میشود. در این حالت پارامترهای سیستم کاملاً مطابق با داده آموزشی تنظیم میشوند و سیستم قدرت تشخیص خود را برای دادههای جدید از دست میدهد
اگر تعدادی بسته اطلاعات با دستهبندی مشخص داشته باشیم، میتوان یک سیستم یادگیری با ناظر طراحی کرد. اما اگر چنین دادهای موجود نباشد (که با توجه به افزایش تنوع در کاربردها احتمال آن زیاد است)، سیستمهای یادگیری بدون ناظر استفاده میشود که بدون داده آموزشی سعی در یافتن الگو در دادههای جدید دارند. طبیعتاً روش بدون ناظر دقت کمتری نسبت به روش با ناظر دارد.
معماری شبکه مبتنی بر نرمافزار (SDN) که در آن اطلاعات بخشهای مختلف شبکه در یک نقطه مرکزی موسوم به کنترلر گردآوری میشود، امکان پیادهسازی سادهتر روشهای یادگیری ماشین را فراهم میآورد. در این معماری میتوان ترافیک ورودی به شبکه را از نظر کیفیت سرویس به کلاسهای مختلف تقسیم کرد (در لبه شبکه) و سپس بر این اساس به آنها سرویسهای متمایزی ارائه داد. پژوهشگران نشان دادهاند که اگر از یادگیری عمیق بدین منظور استفاده شود، دقت قابل قبولی به دست میآید که با روشهای پیشین قابل دستیابی نیست.
مطلب پیشنهادی

- پیشبینی جریان در شبکه: هر جریان در شبکه شامل تعدادی بسته است که ارتباط منطقی با یکدیگر دارند. برای مثال انتقال اطلاعات یک صفحه وب از سرور به کاربر شامل تعدادی بسته است که یک جریان محسوب میشود. اگر مشخصات آماری جریانها را بدانیم (برای مثال، توزیع طول بستهها و اندازه Burst یک جریان)، میتوانیم منابع شبکه را به گونهای بهتر مدیریت کنیم. در واقع، با دانستن مشخصات جریانها تا حدی آینده را پیشبینی میکنیم و منابع را طوری تخصیص میدهیم که در زمانهای بعدی شرایط مطلوب حفظ گردد یا از وقوع شرایط نامطلوبی همچون ازدحام جلوگیری شود.
در این زمینه، پژوهشگران دانشگاه هاروارد شبکه عمیقی را طراحی کردهاند که مشخصات جریانهای شبکه وایفای را به دست میآورد. در استاندارد وایفای، یک مکانیسم جلوگیری از تصادم بستهها موسوم به CSMA/CA وجود دارد که بهعلت تغییر در زمان ارسال هر بسته با توجه به وضعیت کانال، توزیع آماری جریانها را پیچیده میسازد. با وجود این، طرح پیشنهادی میتواند با نرخ خطای کمی توزیع جریان را تشخیص دهد.
- شبکههای اجتماعی: یکی از موضوعات پژوهشی در حوزه شبکه، مبحث شبکههای اجتماعی آنلاین است که با توجه به رشد محبوبیت این شبکهها در سالیان اخیر (فیسبوک، توییتر و اینستاگرام)، بهشدت مورد توجه بوده است. این مبحث جنبههای مختلفی را دربر میگیرد، از جمله آنالیز رفتار کاربران از نظر مدت زمان حضور در شبکه، میزان و نوع ارتباط با سایرین و تعداد/ کیفیت دوستان. با آنالیز رفتار کاربران، دانشی در ارتباط با نحوه تصمیمگیری آنها حاصل میشود. این دانش قابل استفاده برای ارائه پیشنهادهای بهتر به کاربران است. با اعمال یادگیری عمیق از سوی مدیران این شبکهها (که ذخایر ارزشمندی از دادههای کاربران را در اختیار دارند)، دانش مورد نظر به دست میآید. همچنین، راهکارهایی برای پیشبینی رویکرد جامعه در مسائل سیاسی و اجتماعی با توجه به محتوای به اشتراکگذاری شده در شبکههای اجتماعی با بهرهگیری از یادگیری عمیق پیشنهاد شده است.
کاربردهای دیگری نیز برای بهرهگیری از مزایای یادگیری عمیق در شبکه مطرح شده است. مدیریت شبکههای شناختگر و تحلیل حرکت کاربران در شبکههای بیسیم از جمله این موارد هستند که از بررسی آن صرف نظر خواهد شد و خواننده علاقهمند میتواند به مراجع پژوهشی مراجعه کند. در بخش بعدی، به مسیریابی که یکی از مسائل دیرین شبکه است، خواهیم پرداخت و نقش یادگیری عمیق را در آن نظارهگر خواهیم بود.
مطلب پیشنهادی

یادگیری عمیق برای مسیریابی
یافتن مسیر مناسب برای جریانهای مختلف در شبکه اهمیت بالایی دارد و اگر بهدرستی انجام نشود، به بروز ازدحام در شبکه و یا بهرهوری پایین منابع منجر خواهد شد. این مسئله از همان ابتدای شکلگیری شبکههای کامپیوتری مطرح بوده و روشهای فراوانی برای آن ارائه شده است. یکی از روشهای مرسوم، روش کوتاهترین مسیر است که به محاسبه و تعیین کوتاهترین مسیر از نظر هزینه میپردازد. مشکل این روش همگرایی آهسته در محیط دینامیک است که در آن وزن یالهای گراف شبکه متغیر است.
همانند مسائلی که در بخش قبلی بررسی شد، یادگیری عمیق این توانایی را دارد که برای مسئله مسیریابی نیز استفاده شود. این موضوع را با ذکر یک مثال بررسی میکنیم. شبکه شکل 4 را در نظر بگیرید که شامل 16 روتر است و در آن روترهای لبه (مشکی رنگ) از طریق روترهای مرکزی (خاکستری رنگ) به یکدیگر ترافیک ارسال میکنند. لازم است هرکدام از 12 روتر لبه یک سیستم یادگیری عمیق داشته باشند که ورودی آن وضعیت ترافیکی شبکه و خروجی آن بهترین مسیر است. وضعیت ترافیکی شبکه در سادهترین حالت یک ماتریس 12 در 12 است که مشخص میکند هر روتر قرار است به کدام روتر اطلاعات ارسال کند. خروجی نیز یک ماتریس است که مسیر را بهازای هر جفت مبدأ ـ مقصد مشخص میکند. (شکل 4)
 شکل 4
شکل 4
سخن آخر
مقالهای که مطالعه کردید، مطرح ساختن این واقعیت است که اگر یادگیری ماشین در پردازش تصویر، پردازش گفتار، خودروهای بدون سرنشین، بازیهای رایانهای و انبوهی دیگر از کاربردها نقش مهمی بازی میکند، این توانایی را دارد که در مهندسی شبکه نیز به کار گرفته شود. البته نیاز است که مدلهای مناسبی برای این کار ایجاد شود (به نظر میرسد یادگیری عمیق یک گزینه قابل دفاع باشد) و دیگر اینکه داده کافی برای آموزش سیستم یادگیری وجود داشته باشد (که رشد روزافزون ترافیک اینترنت این نیاز را برآورده میسازد). به هر حال، پیچیدگی شبکههای کامپیوتری آن چنان افزایش یافته است که بهزودی باید از کامپیوترها برای مدیریت ارتباطات بین خودشان کمک بگیریم. البته نباید فراموش کرد که ساخت و توسعه مدلهای یادگیری ماشین همچنان در گرو هوش و خلاقیت انسان است
==============================
شاید به این مقالات هم علاقمند باشید:




ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.























نظر شما چیست؟